
Key points of the study :
- The aim of this study is to compare different embedded large language models on smartphones in terms of their performance, energy consumption and environmental impact.
- The carbon footprint of a task can vary by a factor of 18 depending on the model, framework and backend used.
- Hardware acceleration (GPU/TPU) reduces energy consumption by a factor of 3.8 compared with the CPU, for the same task, but also reduces response time by up to 39%. Be careful, however, not to push hardware renewal.
- Even the way in which the response is rendered, via progressive text display (streaming) has a measurable impact: a difference of up to 12% on final energy consumption.
- Using a model with fewer parameters can have a lower impact.
- Measurement is essential, the measured energy impact may be 5 times lower than generic estimates.
Introduction
Artificial intelligence is transforming the way we interact with our smartphones. Rephrasing, automatic replies, correcting spelling mistakes, summaries… Its skills are becoming more and more sophisticated and are frequently called upon, if not continuously active. A growing proportion of these calculations now operate directly on our devices, without sending our data to remote servers. This is what is known as ‘on-device’, local or embedded AI.
Behind the promise of improved responsiveness and respect for privacy lie important environmental issues. As we discussed in a previous article, running these AI models directly on the smartphone requires more energy. This additional consumption during use contributes to the digital carbon footprint. What’s more, this constant or repeated load on components, particularly the battery, accelerates wear and tear and reduces the lifespan of the device. This is likely to encourage premature replacement, exacerbating the ecological impact of manufacturing new terminals and managing electronic waste. This second article focuses specifically on assessing the environmental impact of embedded AI dedicated to text on Android.
It is crucial to note that the alternative – performing these tasks on remote servers – also has its own environmental footprint, via the impact of data centres.
To explore this question, we are going to analyse and compare three technical solutions that enable us to use large language models (LLMs) directly on our phones, bearing in mind their technical specificities and potential areas of application:
- Llama.cpp: an open-source project that allows large language models, initially those of Meta (Llama), to be run on consumer hardware, including smartphones. It is renowned for its ability to run these powerful models with limited resources.
- Android AICore: a set of system services integrated into recent versions of Android. It is designed to run local AI models to improve latency and privacy.
- MediaPipe: an open-source framework from Google. It provides tools for analysing and generating text adapted for mobile use.
By comparing these three approaches, we will seek to understand their capabilities and performance, as well as their energy consumption and the resulting implications for the user and the environment.
Impact of text generation
Methodology
Using Greenspector Studio1, we measured the time and energy consumed to generate and display a response, and assessed the environmental impact of the response.
For each test, a new conversation was initiated, then the same prompt was asked of the model 5 times in a row: Write 10 haikus. The responses generated will therefore all be roughly the same shape, and we can estimate their size at around 170 tokens.
Measurement context
- Google Pixel 8, Android 15, equipped with a TPU (Tensor Processing Unit, designed for large-scale, low-precision calculations).
- Network: off
- Brightness: 50%
- Tests carried out over a minimum of 3 iterations to ensure reliability of results
- Theme: dark (to limit screen power consumption)
Llama.cpp – Private AI
Our first approach uses Llama.cpp, a popular open-source project for running a wide variety of large language models (LLMs) on standard hardware, including smartphones, thanks to its flexibility and the support of a large community. For these tests, we used Llama.cpp targeting only the Pixel 8 CPU.
Measurement context
- Framework : Llama.cpp
- App package : us.valkon.privateai
- Models tested :
Performance
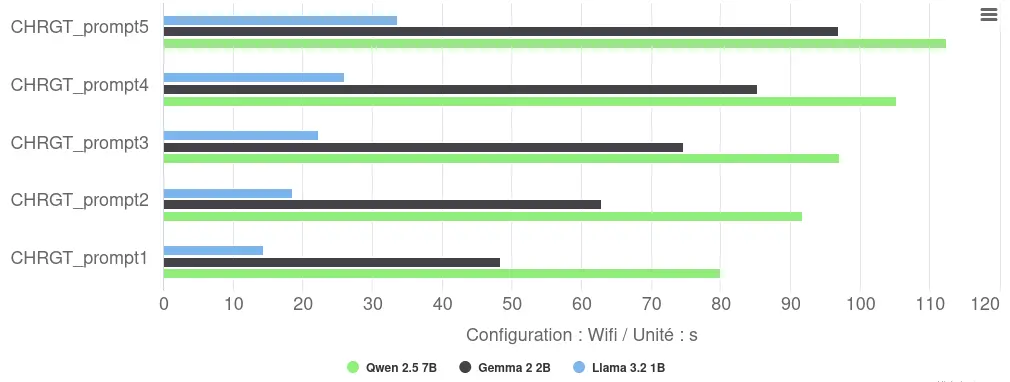
Execution on CPU via Llama.cpp reveals variable performance:
- Response time: there was considerable variability between repetitions (Llama: 14-34s), probably due to ‘cold start’ effects or thermal throttling during consecutive executions.
- Ranking by performance: Llama dominates with an average of 23s, ahead of Gemma (74s, or +222%) and Qwen (98s, or +326%). This hierarchy follows the number of parameters for each model.
- Inference speed: this varies on average between 2 tokens/s (Qwen) and 7 tokens/s (Llama).
Energy consumption
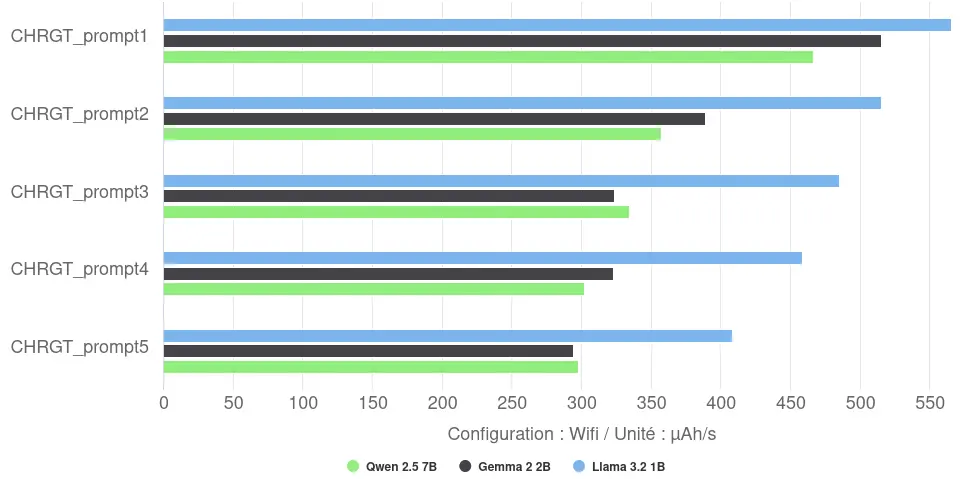
Analysis of the discharge speed reveals a notable fact: the fastest model (Llama) displays the highest discharge speed (487 µAh/s on average), potentially managing to saturate CPU cores more efficiently. Conversely, the larger and slower models (Gemma and Qwen) show a lower average discharge speed (around 350-370 µAh/s), suggesting a different or less intense use of CPU resources over their longer runtimes. The rate of discharge decreases with each iteration: the first iteration is therefore faster but discharges the battery more quickly.
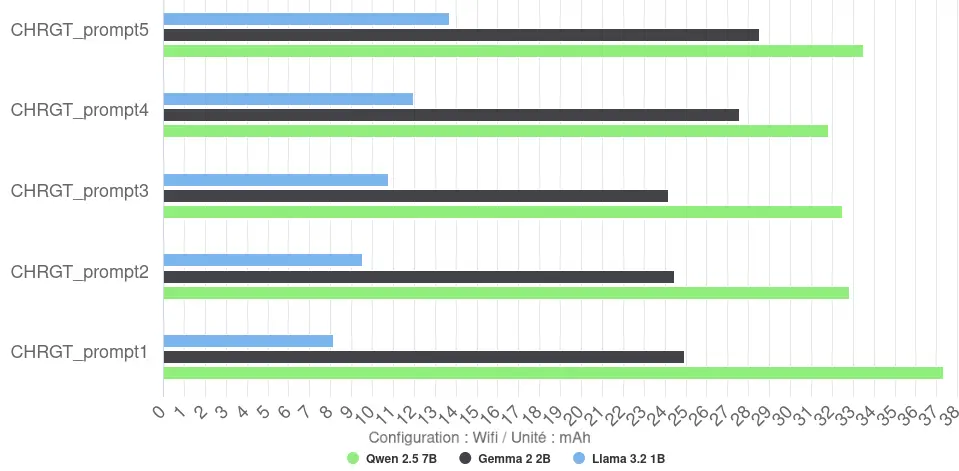
Total energy consumption per response (measured in mAh) is more nuanced. However, there are big differences between the models, ranging from an average of around 11 mAh for Llama to 34 mAh for Qwen.
Efficiency is low for these CPU configurations: Llama reaches 16 tokens/mAh, while Gemma and Qwen fall to 7 and 5 tokens/mAh respectively.
Environmental impact
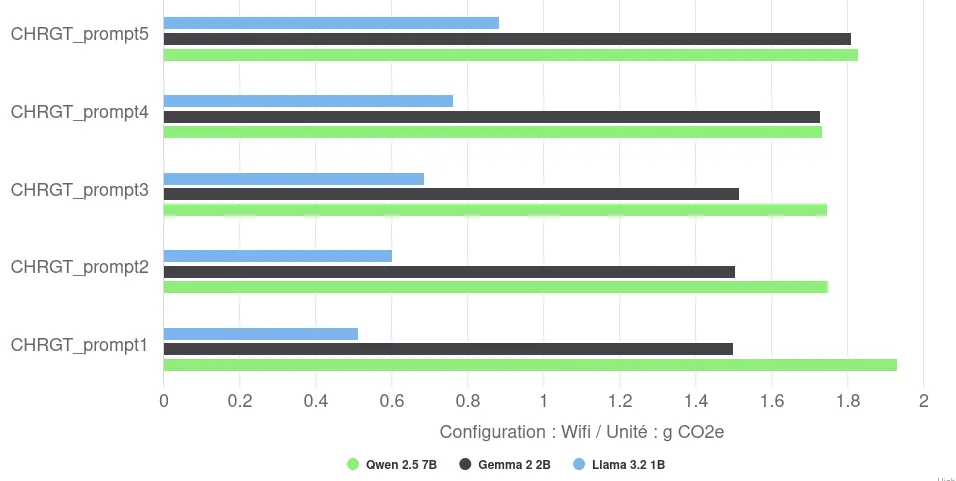
The environmental impact will also vary depending on the response and the model. For example, the average environmental impact will vary between 0.7g CO2e for Llama and 1.8g CO2e for Qwen, for the generation and display of a response of 170 tokens.
A first good practice seems to be to limit the number of model parameters.
Conclusion
Tests using Llama.cpp on CPUs give us an initial idea of the impact of executing LLMs on mobiles. Despite the flexibility of the tool and the use of quantified models (int4/int5, which we’ll come back to in the MediaPipe – Llm Inference section), performance remains very low (between 2 and 7 tokens/s) and total energy consumption high (between 11 and 34 mAh/response), resulting in low energy efficiency (between 5 and 16 tokens/mAh). The counter-intuitive observation of higher instantaneous power for the fastest model (Llama) highlights the complexity of CPU optimisation.
This low efficiency translates into a high environmental impact (per response, France, Greenspector methodology). The impact varies from 0.7 gCO2eq for the lightest model to 1.8 gCO2eq for the heaviest tested, i.e. a factor of 2.6 between the two extremes of this group.
These results highlight that while Llama.cpp offers broad access to models, relying solely on the CPU, even with quantified models, remains a slow and energy-intensive approach for this type of task.
Android AICore – Gemini nano
Gemini Nano is a Google proprietary model executed via Android AICore. AICore is a set of system services integrated into Android, facilitating the optimised and secure execution of on-device AI models, in particular via the Google AI Edge framework and by exploiting hardware accelerators such as the TPU on the Pixels.
Gemini Nano is a multimodal, multilingual model, specifically designed by Google for local processing. It is available in two variants:
- Nano-1 : 1.8 billion parameters, int4 quantification
- Nano-2 : 3.25 billion parameters, int4 quantification
The SDK used does not explicitly specify which variant (Nano-1 or Nano-2) is downloaded and executed by AICore. However, given the size of the model downloaded on our test device, we can assume that it is the Nano-1 variant (1.8B parameters).
Measurement context
- Framework: Google AI Edge
- App package: com.google.ai.edge.aicore.demo
- Model tested: Gemini Nano-1 (Google), 1.8 billion parameters, int4 quantification
- Configurations tested:
- Kotlin implementation, Streaming disabled.
- Kotlin implementation, Streaming enabled.
- Java implementation, Streaming disabled.
- Implemented in Java, Streaming enabled.
Streaming here refers to the progressive display of generated text (token by token), offering a response that is perceived as more dynamic, as opposed to block display once the entire generation has been completed (Streaming deactivated).
Performance
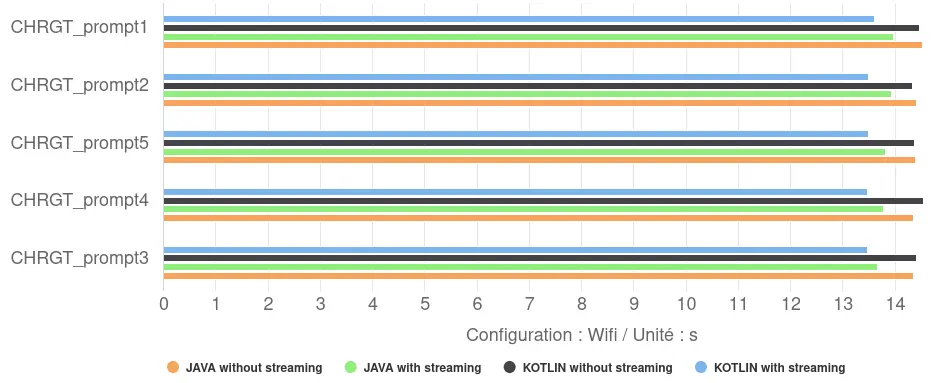
- Kotlin vs Java impact: our tests showed only a minimal difference between the Kotlin and Java implementations in the demo application. Kotlin was very slightly faster (by around 2%) only when streaming was enabled.
- Performance level: average response times are in a narrow range, between 13.5 and 14.4 seconds. They have a generation speed of around 12 tokens/s, which is between 70% and 600% faster than our models with Llama.cpp.
- Streaming impact: enabling streaming had a consistently positive effect on the total measured response time, reducing it from 4% to 6%. Rather than an acceleration of the generation itself, this suggests a better management of the workflow: the application can start displaying the beginning of the response while the generation continues, thus reducing the overall perceived delay between the request and the end of the display.
Energy consumption
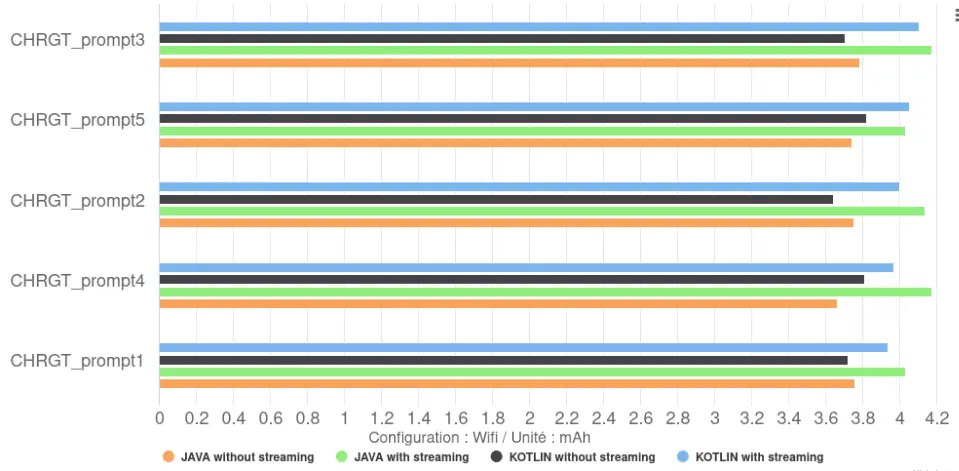
- Impact Kotlin vs Java: the choice between Kotlin and Java had a negligible impact on the total discharge or the rate of discharge of the battery.
- Impact of Streaming: configurations without streaming cause a slightly lower total discharge than those with streaming. This gives them a higher efficiency, 46 tokens/mAh compared with 41 tokens/mAh for the models with streaming, i.e. an increase of 12%. They are clearly superior to those using Llama.cpp, which had a maximum of 16 tokens/mAh.
A second good practice seems to be not to use the progressive display, which increases efficiency (tokens/mAh) by 12%.
- This difference is directly linked to the battery discharge speed: it is lower without streaming (259 µAh/s) than with streaming (296 µAh/s), an increase of 14%. This increase in discharge speed in streaming mode is correlated with increased CPU usage by the application itself (4-6% CPU usage with streaming compared with just 0.5% without streaming). This is because progressive display requires the CPU to process and display tokens as they arrive from the model, whereas in non-streaming mode the CPU remains largely inactive during generation. This can be seen in the graphs below.
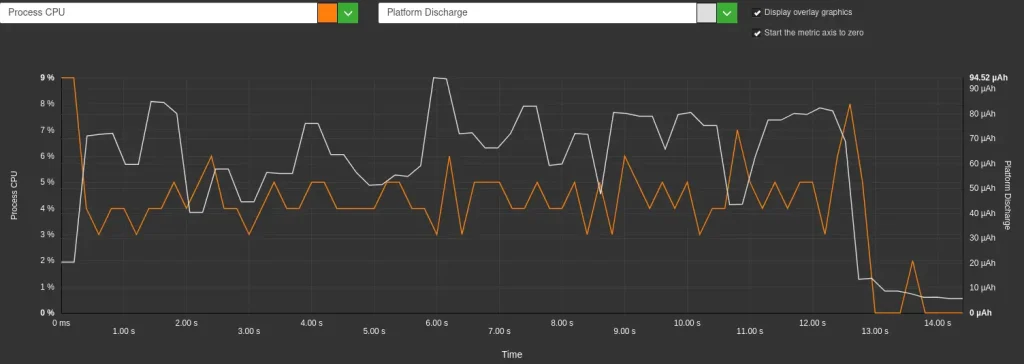
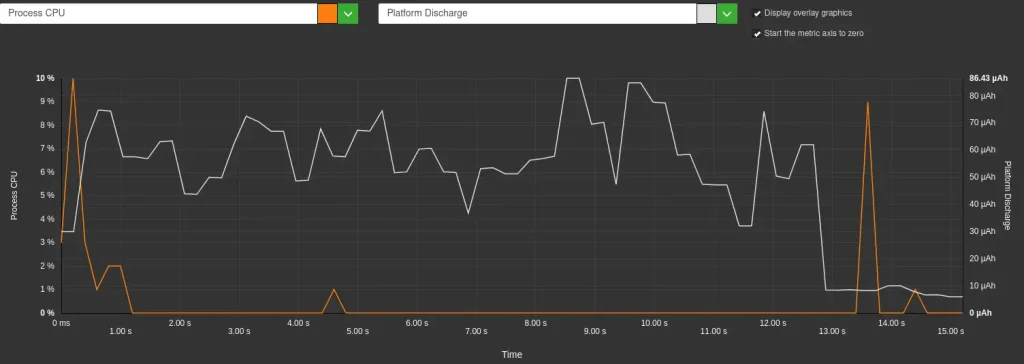
Environmental impact
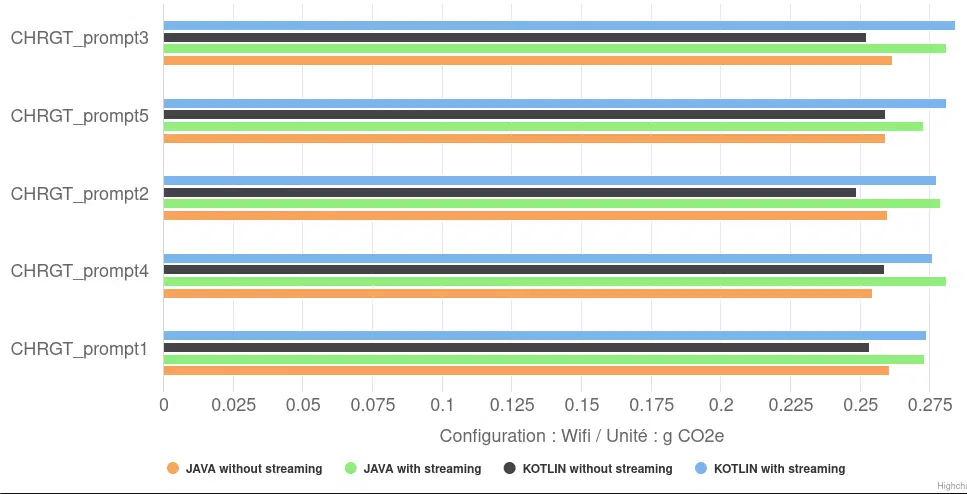
In terms of environmental impact, configurations without streaming are logically the most sober, with 0.26 gCO2eq on average, i.e. around 8% less than those with streaming (0.23 gCO2eq on average). Although this absolute impact per response is significantly lower than that of Llama.cpp configurations (up to 1.8 gCO2eq), it remains sensitive to the choice of application implementation.
Conclusion
Gemini Nano’s analysis via Android AICore reveals a stable and optimized execution for the Pixel 8’s dedicated hardware (TPU) and highlights some important trade-offs:
- Streaming display, while improving perceived responsiveness, increases energy consumption and hardware load. This is mainly due to the additional CPU load placed on the application to manage the progressive display.
- The choice of implementation language (Kotlin or Java) had a negligible impact on performance and energy in this context.
From an environmental impact point of view, it is lower than with integrations with Llama.cpp, but the high level of integration with specialist hardware (NPU/TPU), while increasing energy efficiency, may increase the pressure to renew devices in order to access the latest AI functionalities, a key factor in the environmental impact of digital technology.
MediaPipe – Llm Inference
We end our analysis with MediaPipe, Google’s open-source framework. Although known for its multimedia processing solutions, MediaPipe also offers a LlmInference API specifically designed and optimised to run language models directly on mobile devices, making it particularly relevant to this study. For our tests, we used the example application provided by Google.
Measurement context
- Framework: MediaPipe
- App package: com.google.mediapipe.examples.llminference
- Models used:
- Gemma 1.1 (Google): 2 billion parameters, int4 and int8 quantification, CPU or GPU backend.
- Gemma 3 (Google): 1 billion parameters, int4 quantification, CPU or GPU backend.
- DeepSeek-R1-Distill-Qwen (Deepseek): 1.5 billion parameters, int8 quantification, CPU backend.
- Phi-4-mini-instruct (Microsoft) : 3.8 billion parameters, int8 quantification, CPU backend.
Quantification is a technique for ‘compressing’ models and making them faster. Int8 corresponds to light compression and int4 to stronger compression.
The choice of backend determines the main computing unit:
- CPU: uses the main processor cores (Central Processing Unit) of the smartphone.
- GPU: calls on the graphics processor (Graphics Processing Unit), which, on the Google Pixel 8, can delegate some or all of the calculations to the NPU/TPU (Neural/Tensor Processing Unit) for greater efficiency in AI tasks.
Let’s now look at how these different configurations (models, quantification, backend) behave in terms of time, energy consumption and environmental impact during the execution of our haiku generation task.
Performance
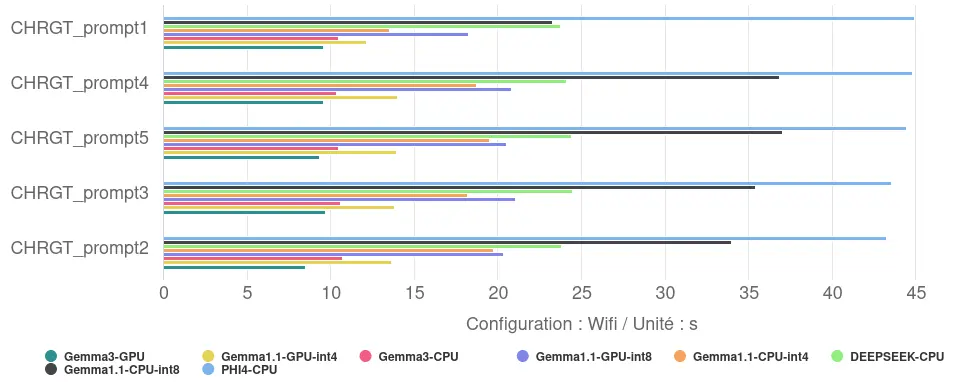
The measurements reveal significant differences in performance between configurations:
- Response time: the time taken to generate the 10 haikus ranged from 9.3 seconds for the fastest configuration (Gemma 3, 1B, on GPU) to 44.2 seconds for the slowest (Phi-4-mini, 3.8B, on CPU). The maximum response time is therefore almost five times greater than the minimum time observed.
- Inference speed: this corresponds to a speed ranging from around 18 tokens/s for the fastest configuration to 4 tokens/s for the least efficient.
- The impact of using the GPU: using the GPU improves performance. For Gemma 1.1 (2B), the transition from CPU to GPU reduces response time by 39% (in int8) and 25% (in int4). For Gemma 3 (1B), this reduction is 11%.
- The impact of quantification: model compression via quantification is also proving effective. For Gemma 1.1 (2B), using int4 (more aggressive) quantification compared with int8 speeds up the model by 46% on the CPU and 33% on the GPU.
- The combined effect of the optimisations: by combining the use of the GPU and int4 quantification, the response time of Gemma 1.1 is reduced by almost 60% compared with the int8 configuration on the CPU (from 33.3s to 13.5s). This underlines the value of applying these optimisation techniques together.
- Size/optimisation relationship: the results show that the raw size of the model is not the only factor determining performance. The smallest model (Gemma 3, 1B) obtained the best time when optimised for the GPU. However, a larger model (Gemma 1.1, 2B) with advanced optimisations (int4/GPU) outperforms a less optimised configuration of a smaller model (here, Gemma 3 int4/CPU, although the difference is small). The largest model tested (Phi-4-mini, 3.8B), evaluated here without GPU or int4 optimisation, has the longest response times.
Energy consumption
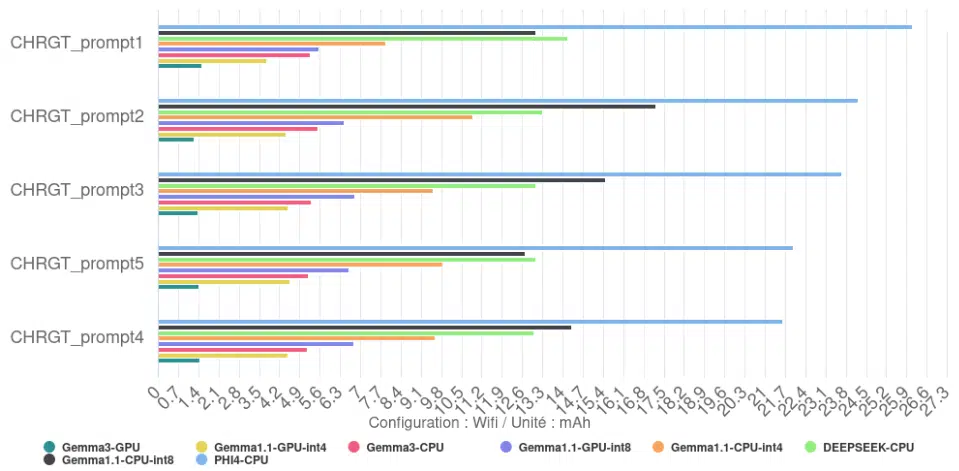
Unsurprisingly, the total energy consumed to generate the 10 haikus is directly related to the execution time. The slowest configurations, such as Phi-4, consume the most energy in total to complete the task. Conversely, the fastest configuration, Gemma 3 GPU, is also the one that consumes the least total energy for the same task.
We see an efficiency of 123 tokens/mAh for Gemma 3 with the GPU backend, compared with just 7.5 tokens/mAh for Phi-4-mini with the CPU backend.
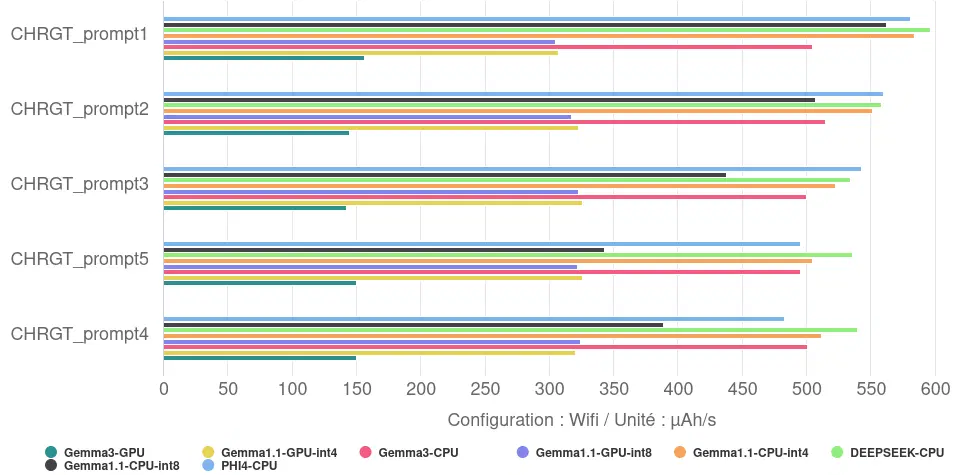
Analysis of the discharge speed reveals more nuanced information about the load on the equipment:
- Very high load: several CPU configurations show a high battery discharge during execution (more than 500 µAh/s on average), indicating an intense load on the processor: this is the case for DEEPSEEK on CPU, Gemma 1.1 CPU int4, PHI4-CPU and Gemma 3 CPU.
- High load: the GPU versions of Gemma 1.1 (int4 and int8) and the int8 CPU version of Gemma 1.1 are at an intermediate level (320 µAh/s for the GPUs, 448 µAh/s for the int8 CPU), which still corresponds to more or less ten times our reference consumption (phone screen on, on the background).
- Average load: Gemma 3 GPU stands out for its lower battery discharge rate than the others (149 µAh/s on average), which is 3 to 4 times lower than the most demanding. Even so, this consumption corresponds to more than 4 times our reference.
- Impact of the backend (CPU vs GPU): our measurements clearly show that, for a given model (Gemma 1.1 and Gemma 3), using the GPU systematically resulted in a lower battery discharge rate (µAh/s) than using the CPU. So not only is the GPU faster, it also consumes less power. This reduction varies from minus 29% for Gemma 1.1 int 8 to over 70% for Gemma 3.
- Impact of quantification (int4 vs int8): the effect of quantification on instantaneous power is mixed:
- Sur CPU (Gemma 1.1) : la version int4 a une vitesse de décharge de la batterie plus élevée que la version int8.
- Sur GPU (Gemma 1.1) : il n’y a pas de différence notable entre int4 et int8.
- Le gain de vitesse apporté par la quantification int4 sur CPU se fait donc au prix d’une sollicitation instantanée plus forte du processeur.
Environmental impact
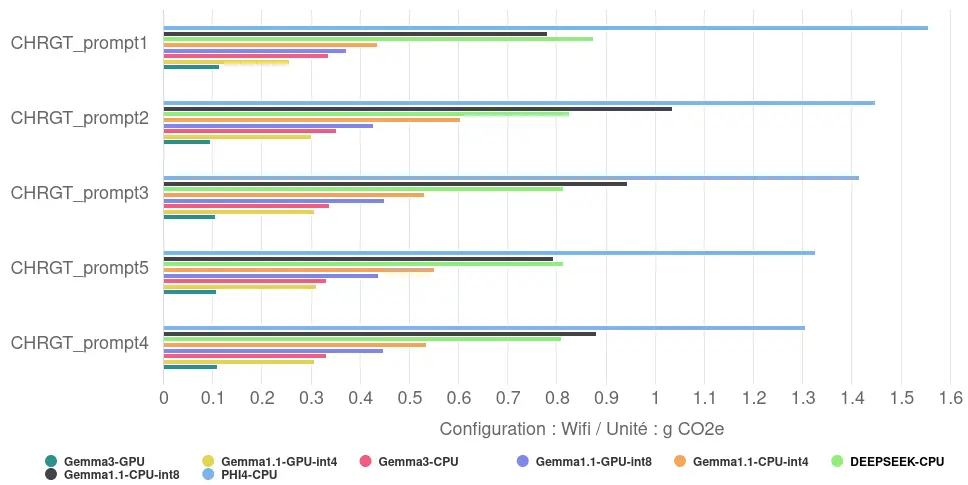
Translated into environmental impact, the generation and display of responses in France reveals a considerable gap: from 0.11 gCO2eq on average for the most sober configuration (Gemma 3/GPU) to 1.41 gCO2eq on average for the least efficient (Phi-4-mini/CPU). This factor of 13 underlines the importance of optimising software and hardware in a coordinated way.
Conclusion
These tests on MediaPipe confirm that technical choices (model, CPU/GPU backend, quantification) dictate performance and energy consumption. A poorly optimised configuration degrades the user experience and autonomy, unlike efficient solutions, underlining the central challenge of embedded AI.
A third best practice seems to be to use a hardware accelerator (NPU/TPU or, failing that, the GPU) instead of the CPU: this enables the model to perform the same task between 11% and 39% faster, while consuming between 2.2 and 3.8 times less energy.2
Conclusion
Our comparison of the three approaches reveals a clear hierarchy in terms of performance, energy efficiency and environmental impact for local text AI (based here on generating and displaying a text of 170 tokens).
Performance
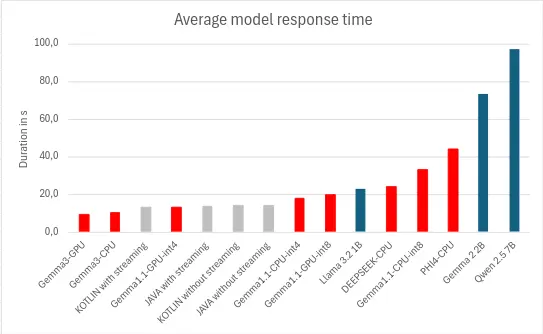
Our models took an average of 28.2s to generate and display the response, with a minimum of 9.3s and a maximum of 97.3s, giving a generation speed of between 2 and 18 tokens/s. The most decisive factors appear to be :
- The number of parameters: the fewer the parameters, the better the model will perform (llama.cpp)
- Using a hardware accelerator: using a GPU, TPU or NPU can significantly improve performance. (MediaPipe)
- Quantification: the use of more aggressive quantification seems to improve performance. (MediaPipe)
This performance is still quite low compared with server-based iterations, where the inference speed can reach 90 tokens/s.3
Energy consumption
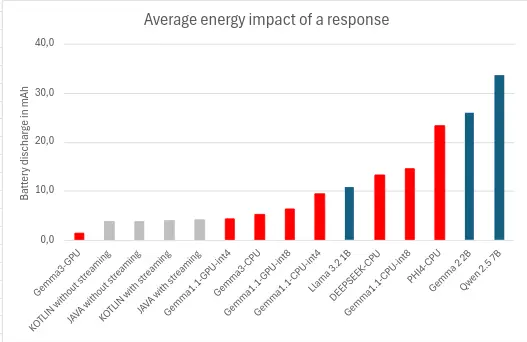
To generate and display the response, our models consumed an average of 11mAh, with a minimum of 1.4mAh and a maximum of 33.6mAh. The most decisive factors appear to be :
- Response time: the longer the response time, the more the model will consume.
- Use of a hardware accelerator: using a GPU, TPU or NPU significantly reduces battery discharge (MediaPipe).
- Streaming: using progressive display will lead to excessive energy consumption. (AndroidAICore)
Our results also show how decisive the specific configuration is: our measurement for Gemma 2 2B (int5/CPU/Llama. cpp) at 0.11 Wh/response (with a nominal battery output voltage of 3.89Volts4) turned out to be around 5 times more economical than figures taken from the Ecologits Calculator tool on Hugging Face5 for the same model in a different context: 0.51 Wh for 170 tokens, highlighting the importance of the execution context, as well as the importance of measurement.
Environmental impact
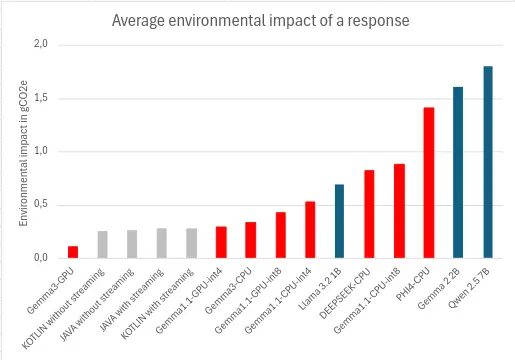
To generate and display the response, the average environmental impact is estimated at 0.7gCO2e, with a minimum of 0.1gCO2e and a maximum of 1.8gCO2e, a difference of a factor of 18.
Here again, the specific configuration is decisive: our evaluation for Gemma 2 2B (int5/CPU/Llama.cpp) at 1.6 gCO2e/response turned out to be around 5 times greater than the figures taken from the Ecologits Calculator tool on Hugging Face for the same model in a different context: 0.316 gCO2e for 170 tokens, again underlining the importance of the execution context.
While dedicated AI chips (NPUs/TPUs), which are becoming increasingly common, are helping to improve the efficiency and therefore the environmental impact of responses, the growing demand for these capabilities is also likely to accelerate the renewal of devices, adding to the overall environmental footprint of digital technology.
Sources
- https://saas.greenspector.com/en ↩︎
- It is important that this good practice does not encourage users to change their equipment in order to use it, as the environmental gain is negligible compared to keeping their equipment for as long as possible. ↩︎
- https://www.inferless.com/learn/exploring-llms-speed-benchmarks-independent-analysis ↩︎
- https://www.ifixit.com/products/google-pixel-8-battery-genuine ↩︎
- https://huggingface.co/spaces/genai-impact/ecologits-calculator ↩︎
