Disclaimer : Ceci n’est pas un article d’un expert SEO mais d’un expert écoconception inspiré par l’intéressante conférence d’Erlé Alberton Comment hacker Google grâce à la data SEO
Les algorithmes SEO de Google
Crawling, pilier de l’algorithme
Les algorithmes SEO de Google se basent sur 3 domaines :
- le crawling qui va permettre à Google d’évaluer vos pages en termes de temps de réponse, de qualité technique ;
- l’indexation qui va analyser le contenu (fraîcheur, richesse, qualité…) ;
- le ranking pour analyser la popularité de votre site.
Le crawling est une des parties les plus importantes, car c’est la manière dont Google va « afficher » vos pages. Les robots de Google (ou GoogleBots) vont analyser chaque url et les indexer. Le processus est itératif : les bots reviendront régulièrement réanalyser ces pages pour identifier les éventuels changements.
La notion de Crawl budget
L’effort que les bots de Google vont fournir pour analyser votre site va influencer le nombre de pages qui seront référencées, la fréquence des vérifications ultérieures, ainsi que la notation globale de votre site. L’algorithme de Google est en effet dicté par un « effort maximum à fournir » qu’on appelle le « crawl budget« . Google le définit comme ceci:
Crawl rate limit
Googlebot is designed to be a good citizen of the web. Crawling is its main priority, while making sure it doesn’t degrade the experience of users visiting the site. We call this the « crawl rate limit » which limits the maximum fetching rate for a given site. Simply put, this represents the number of simultaneous parallel connections Googlebot may use to crawl the site, as well as the time it has to wait between the fetches. The crawl rate can go up and down based on a couple of factors:
Crawl health: if the site responds really quickly for a while, the limit goes up, meaning more connections can be used to crawl. If the site slows down or responds with server errors, the limit goes down and Googlebot crawls less.
…
Autrement dit, Google ne veut pas passer trop de temps sur votre site, pour pouvoir consacrer du temps aux autres sites. Donc s’il détecte des lenteurs, l’analyse sera moins poussée. Toutes vos pages ne seront pas indexées, Google ne reviendra pas si souvent, résultat : vous allez perdre en référencement.
Une autre explication à cette logique de budget, est que le crawling coûte de la ressource serveur à Google et que cette ressource a un coût. Google est une entreprise non philanthropique. Il est compréhensible qu’elle veuille limiter ses coûts de fonctionnement tel que celui du crawling. Au passage, cela permet aussi de limiter l’impact environnemental de l’opération, ce qui est un point important pour Google.
Sachez où vous en êtes
Il est donc nécessaire de surveiller le budget crawling et la manière dont Google analyse votre site. Cela peut se faire de différentes manières.
Vous pouvez utiliser la console Google Search Crawl-stat.
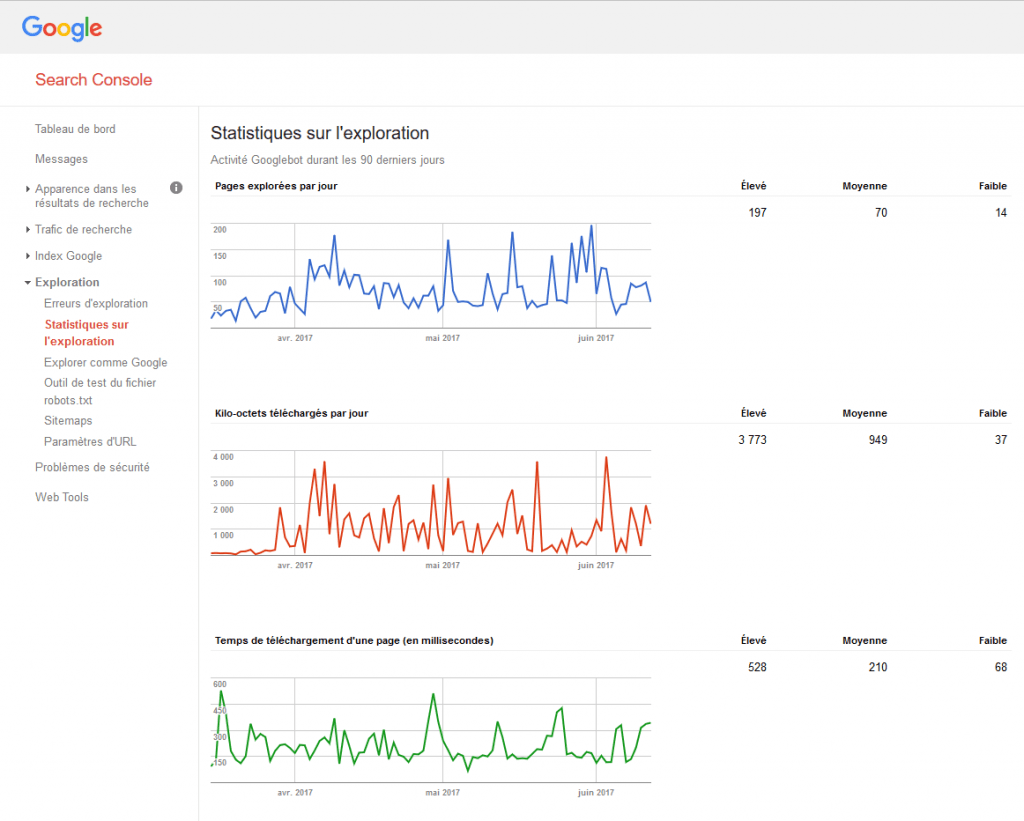
La fenêtre d’erreur Crawl-error est importante : elle va vous indiquer les erreurs que le robot a rencontrées lors du crawl.
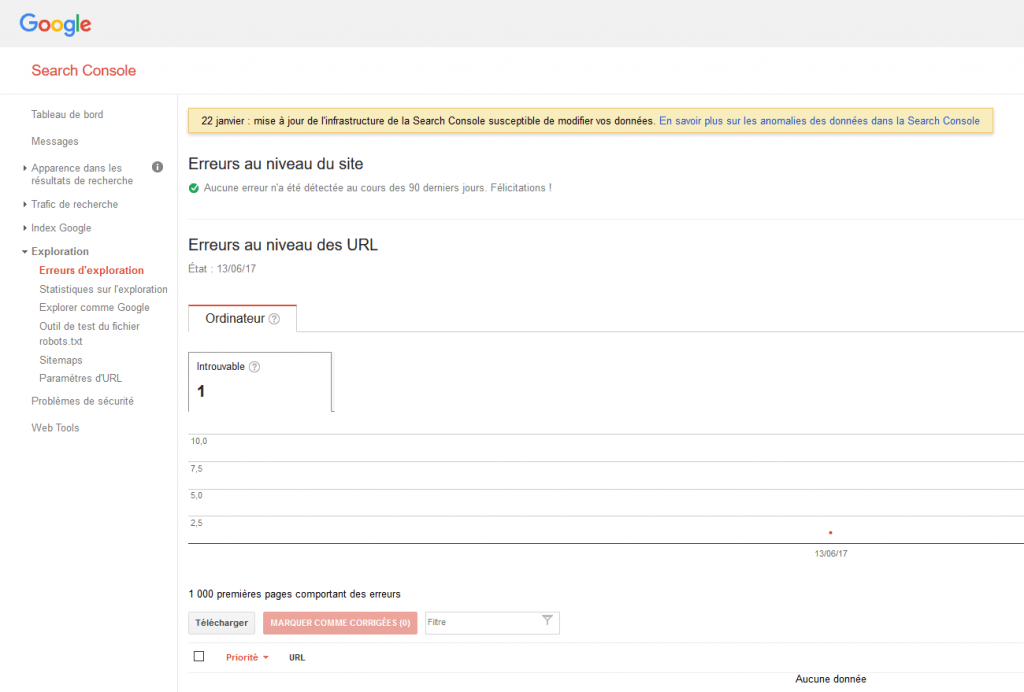
Plusieurs types d’erreurs sont possibles, mais ce qui est sûr c’est qu’une page trop lente à charger sera mise en erreur (timeout du bot). Je rappelle que Google ne veut pas passer trop de temps à crawler votre site, il a mieux à faire. Vous trouverez ici plus d’explications sur les erreurs.
Plus technique : vous pouvez aller voir dans les logs de vos serveurs ce qu’ont fait les bots.
Voici par ailleurs, la liste des robots qui sont pris en compte dans le budget de crawl de Google Search console.
Enfin, vous pouvez simuler la façon dont Google va « voir » votre page. Toujours dans la console Google Search, utilisez l’option Crawl comme Google.
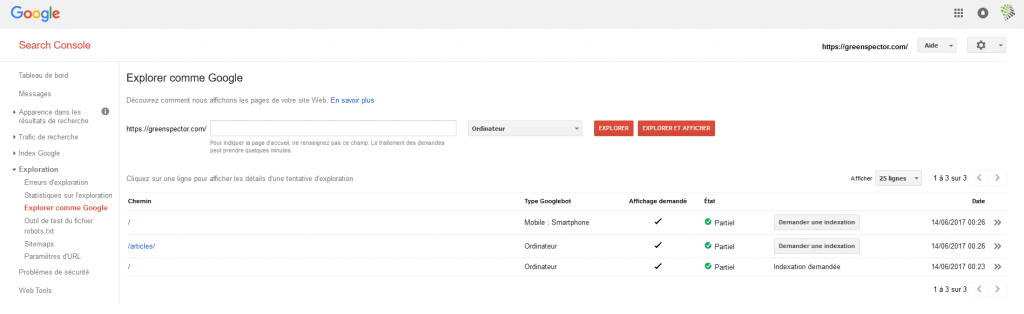
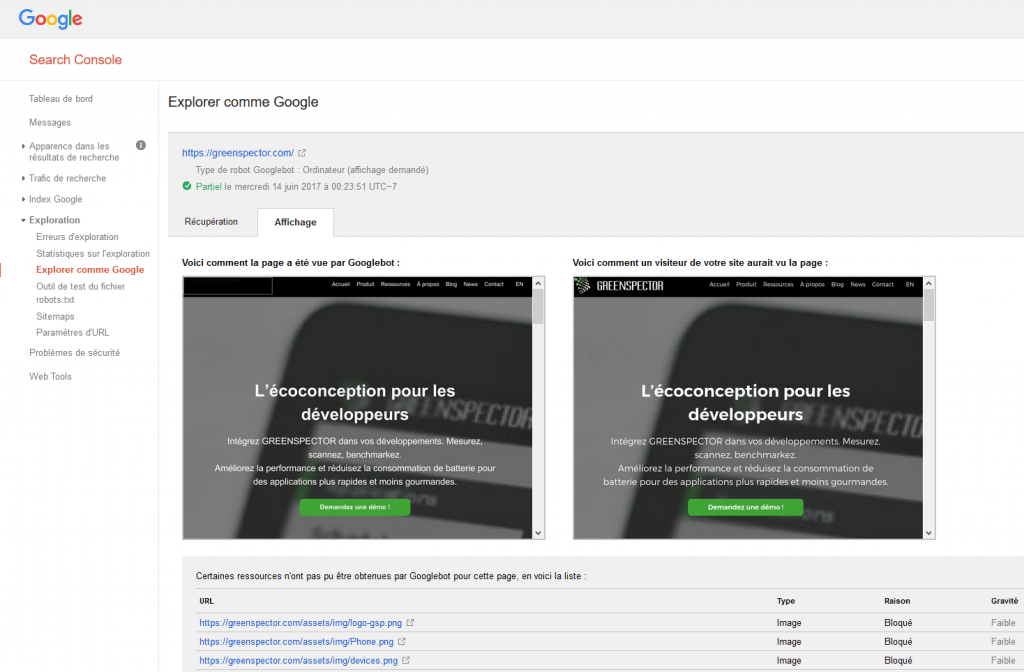
Voila, vous savez maintenant comment Google crawle et voit votre site ! Bon résultat ou mauvais, le référencement n’est jamais acquis et il faut batailler chaque jour. Nous allons donc voir comment améliorer cela.
Améliorez la performance
Temps de réponse du serveur
Comme vous l’avez compris, GoogleBot se comporte comme un utilisateur : si la page met trop de temps à charger, il abandonne et va sur un autre site. Donc une bonne performance va permettre d’améliorer le nombre de pages crawlées par Google. Un chargement rapide laissera au bot le temps de crawler plus de pages. Indexé plus en profondeur, votre site sera mieux référencé.
Reduce excessive page loading for dynamic page requests.
A site that delivers the same content for multiple URLs is considered to deliver content dynamically (e.g. www.example.com/shoes.php?color=red&size=7 serves the same content as www.example.com/shoes.php?size=7&color=red). Dynamic pages can take too long to respond, resulting in timeout issues. Or, the server might return an overloaded status to ask Googlebot to crawl the site more slowly. In general, we recommend keeping parameters short and using them sparingly. If you’re confident about how parameters work for your site, you can tell Google how we should handle these parameters.
C’est la première limite à respecter : ne pas un dépasser un temps trop long sur le serveur. Trop long ? Difficile de mettre un seuil ! Mais vous pouvez au moins mesurer cette performance avec un indicateur tel que le Time To First Byte (TTFB). C’est le temps entre l’émission de la requête côté client et la réception du premier octet en réponse à cette requête. Le TTFB prend donc en compte le temps de transfert sur le réseau et le temps de traitement côté serveur. Le TTFB est mesuré par tous les outils habituels de gestion de la performance. Le plus simple est d’utiliser les outils de développement intégrés aux navigateurs :
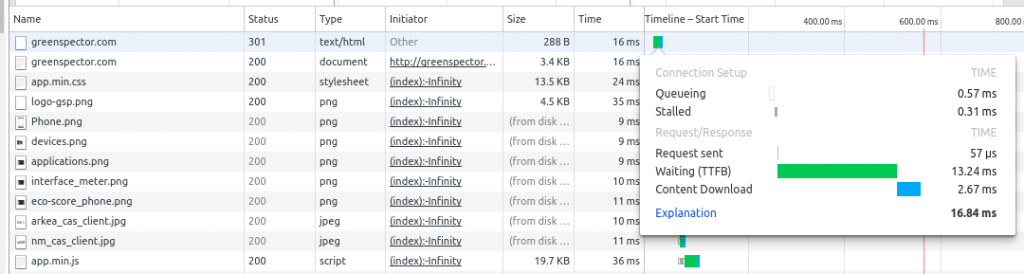
Un seuil normal sera entre 200 et 400 ms. Regardez le temps que vous obtenez, et essayez de le réduire. Comment faire ? Plusieurs paramètres sont à prendre en considération :
- La configuration du serveur : si vous êtes sur un hébergement mutualisé, difficile d’agir ; amis si vous connaissez le responsable infra demandez-lui !
- Le traitement des requêtes. Par exemple si vous être sous un CMS comme WordPress ou Drupal, le temps de génération des pages PHP et d’accès à la base de données ont un impact important. Vous pouvez utiliser les systèmes de cache comme W3cache ou alors un reverse proxy comme Varnish par exemple.
- Un code inefficient côté serveur. Analysez votre code et appliquez les bonnes pratiques d’écoconception.
De cette manière, vous allez faciliter l’accès à vos pages pour vos utilisateurs et surtout éviter les erreurs de crawl de Google.
Performance d’affichage
Difficile de dire à quel point les bots de Google prennent en compte la vitesse d’affichage de votre page mais c’est un paramètre important. Si la page prend 10 secondes à charger, les bots auront du mal à la lire en entier. Comment mesurer cela ? Tout comme pour le TTFB, les outils de développeurs sont utiles. Je vous conseille aussi Web Page Test.
L’idée est de rendre la page visible et utilisable le plus rapidement possible à l’utilisateur. Le plus rapidement possible ? Le modèle RAIL donne des temps idéaux :

En particulier, le R (pour Response) indique un temps inférieur à 1 seconde.
Pour améliorer cela, le domaine de la performance web fourmille de bonnes pratiques. Quelques exemples :
- Utiliser le cache client pour les éléments statiques comme les CSS. Cela permet lors d’une deuxième visite d’indiquer au navigateur (et aussi aux bots) que l’élément n’a pas changé et qu’il n’est donc pas nécessaire de le recharger.
- Concaténer les JS et les CSS ce qui permettra de réduire le nombre de requêtes. Attention, cette bonne pratique n’est plus valide si vous passez en HTTP2.
- Limiter globalement le nombre de requêtes. On voit de nombreux sites avec plus de 100 requêtes. C’est coûteux en termes de chargement pour le navigateur.
Nous aurons l’occasion de revenir dans un prochain article sur la performance web. Au final, si vous rendez votre page performante, ce sera bénéfique pour votre référencement mais aussi pour vos visiteurs !
Aller plus loin avec l’écoconception
La limite de la performance pure
Se focaliser uniquement sur la performance serait une erreur. En effet, les bots ne sont pas des utilisateurs comme les autres. Ce sont des machines, pas des humains. La performance web se focalise sur le ressenti utilisateur (affichage le plus rapide). Or les bots voient plus loin que les humains, ils doivent en effet lire tous les éléments (CSS, JS…). Par exemple, si vous vous focalisez sur la performance d’affichage, vous allez potentiellement appliquer la règle qui conseille de déférer certains codes javascript en fin de chargement. De cette manière la page apparaît rapidement et les traitements continuent ensuite. Or comme les bots ont pour objectif de crawler tous les éléments de la page, le fait que les scripts soient déférés ne changera rien pour eux.

Il est donc nécessaire d’optimiser tous les éléments, y compris ceux qui chargeront une fois la page affichée. On fera particulièrement attention à l’usage du javascript. Google Bot peut le parser mais avec des efforts. On utilisera donc chaque technologie avec parcimonie. Par exemple AJAX a pour but de créer des interactions dynamiques avec la page : oui pour les formulaires ou chargements de widgets… mais non si c’est uniquement pour un chargement de contenu sur un OnClick.
Faciliter le travail du GoogleBot revient à travailler sur tous les éléments du site. Moins il y a d’éléments, plus c’est facile à faire. Donc : Keep It Simple !…
L’écoconception à la rescousse du crawl
L’écoconception des logiciels a pour objectif principal de réduire l’impact environnemental des logiciels. Techniquement, cela se traduit par la notion d’efficience : il faut répondre au besoin de l’utilisateur, en respectant les contraintes de performance, mais avec une consommation de ressources et d’énergie qui soit la plus faible possible. La consommation d’énergie causée par les logiciels (dont votre site web) est donc la pierre angulaire de la démarche.
Comme vous l’avez compris depuis le début de l’article, les bots ont un budget issu d’une capacité limitée en temps mais aussi une facture d’énergie à limiter pour les datacenters de Google. Tiens ? Nous retrouvons ici le but de l’écoconception des logiciels : limiter cette consommation d’énergie. Et pour cela, une approche basée sur la performance ne convient pas : en cherchant à améliorer la performance sans maintenir sous contrôle la consommation de ressources induites, vous risquez fort d’obtenir un effet inverse à celui que vous recherchez.
Alors, quelles sont les bonnes pratiques ? Vous pouvez parcourir ce blog et vous en découvrirez 🙂 Mais Je dirais que peu importent les bonnes pratiques, c’est le résultat sur la consommation de ressources qui compte. Est-ce que les Progressive Web App (PWA) sont bonnes pour le crawling ? Est-ce que le lazy loading est bon ? Peu importe, si au final votre site consomme peu de ressource et qu’il est facile à « afficher » par le bot, c’est bon.
La mesure d’énergie pour contrôler la crawlabilité
Une seule métrique englobe toutes les consommations de ressources : l’énergie. En effet la charge CPU, les requêtes réseaux, les traitements graphiques… tout cela va déboucher sur une consommation d’énergie par la machine. En mesurant et contrôlant le consommation d’énergie, vous aller pouvoir contrôler le coût global de votre site.
Voici par exemple une mesure de consommation d’énergie du site Nantes transition énergétique. On voit 3 étapes : le chargement du site, l’idle au premier plan, et l’idle navigateur en tâche de fond. De nombreuses bonnes pratiques d’écoconception ont été appliquées. Malgré cela, un slider tourne et la consommation en idle reste importante, avec une conso totale de 80 mWh.
On le voit ici, la consommation d’énergie est le juge de paix de la consommation de ressources. Réduire la consommation d’énergie va vous permettre de réduire l’effort du GoogleBot. Le budget énergétique idéal pour le chargement d’une page est de 15 mWh : c’est celui qui permet de décrocher le niveau « Or » du Green Code Label. Pour rappel ici, malgré le respect de bonnes pratiques, la consommation était de 80 mWh. Après analyse et discussions entre les développeurs et le maître d’ouvrage, le slide a été remplacé par un affichage aléatoire et statique d’images : la consommation est retombée sous les 15mWh !
En attendant de vous faire labelliser 🙂 vous pouvez mesurer gratuitement la consommation de votre site sur Web Energy Archive, un projet associatif auquel nous sommes fiers d’avoir contribué.
L’écoconception des fonctionnalités
Améliorer la consommation et l’efficience de votre page, c’est bien, mais cela risque de ne pas suffire. L’étape suivante est d’optimiser aussi le parcours de l’utilisateur. Le bot est un utilisateur ayant un budget ressources limité et devant parcourir le maximum d’URL de votre site avec ce budget. Si votre site est complexe à parcourir (trop d’URL, une profondeur trop importante…) le moteur ne parcourra pas tout le site, ou alors en plusieurs fois.
Il est donc nécessaire de rendre le parcours utilisateur plus simple. Cela revient encore à appliquer des principes d’écoconception. Quelles sont les fonctionnalités dont l’utilisateur a vraiment besoin ? Si vous intégrez des fonctionnalités inutiles, l’utilisateur et le bot vont gaspiller des ressources au détriment des éléments vraiment importants. Outils d’analytics trop nombreux, animations dans tous les sens… demandez-vous si vous avez vraiment besoin de ces fonctionnalités car le bot devra les analyser. Et cela se fera surement au dépit de votre contenu qui – lui – est important.
Pour l’utilisateur, c’est pareil : si obtenir une information ou un service demande un nombre de clics trop important, vous risquez de le décourager. Une architecture de parcours efficiente va permettre d’aider le bot et aussi l’utilisateur. Aidez-vous du sitemap pour analyser la profondeur du site.
Enfin, l’exercice d’écoconception des pages ne sera pas efficace si vous avez un site complexe. Il est possible par exemple qu’avec des urls dynamiques un nombre important d’url soit détecté par Google. Vous aurez alors des urls en double, du contenu inutile… Un nettoyage de l’architecture du site sera peut-être nécessaire ?
Anticiper les algorithmes Mobile First de Google
Prise en compte des nouvelles plateformes
Google veut améliorer l’expérience de recherche des utilisateurs, il prend donc en compte les derniers usages des utilisateurs. Le nombre de visiteurs mobiles excédant maintenant celui des visiteurs desktop, les algorithmes de Google passe au Mobile First. Le planning n’est pas très clair mais plusieurs signes annoncent ce changement.
Vous pouvez anticiper la manière dont Google crawle votre site, toujours via la console Search Crawl, avec l’option Fetch as Mobile.
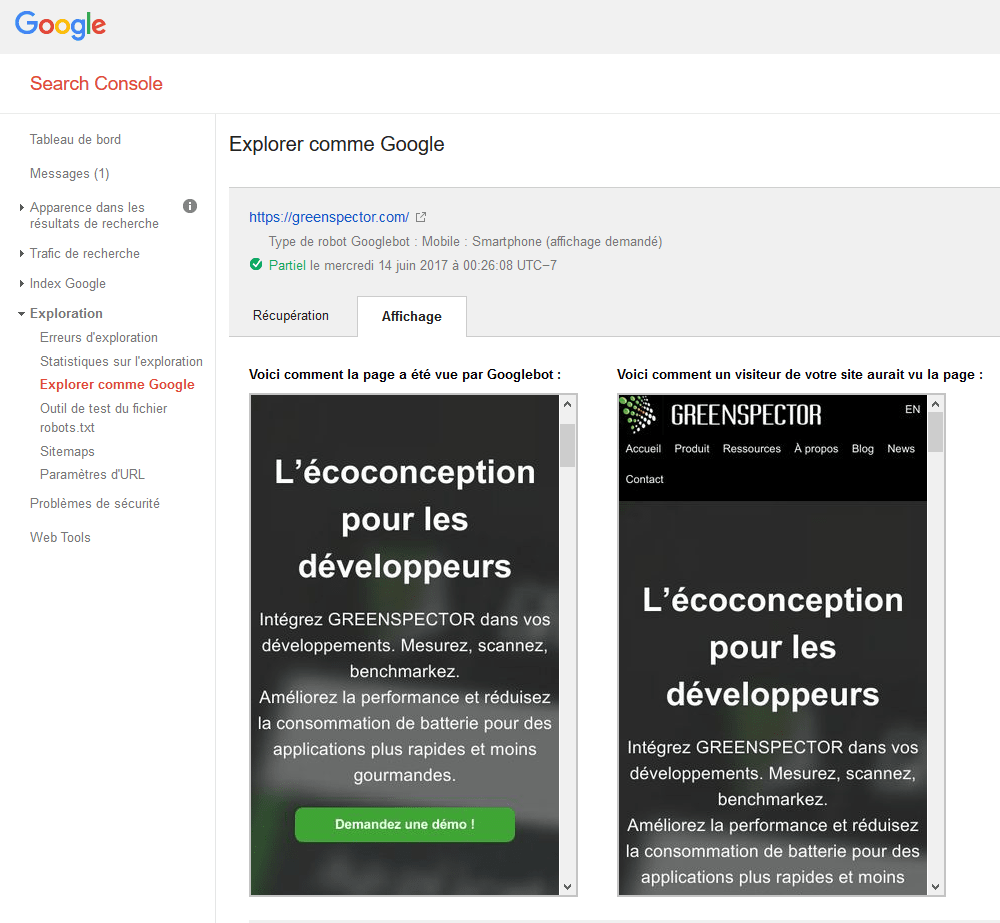
Google propose aussi un site de test pour savoir si votre site est prêt pour le mobile.
La prise en compte de ces contraintes #MobileFirst n’est pas forcément simple pour votre site. Il est probable que cela vous prennent du temps et quelques efforts. Mais c’est le prix à payer si vous voulez avoir un bon référencement dans les prochains mois. En outre, vos visiteurs seront reconnaissants : ils apprécieront que votre site ne décharge plus autant la batterie de leur smartphone.
Pour aller encore plus loin
Reprenons la citation de Google :
Googlebot is designed to be a good citizen of the web.
En tant que développeur ou propriétaire de site, votre ambition doit être de devenir au moins un « aussi bon citoyen du web » que le bot de Google. Pour cela, projetez-vous dans un usage de votre site sur plateforme mobile, mais aussi dans des conditions de connexion bas débit ou d’appareils un peu plus anciens. En réduisant les consommations de ressources de votre site, non seulement vous ferez plaisir au GoogleBot (qui vous récompensera par un meilleur référencement) mais aussi vous donnerez à toute une partie de la population mondiale (y compris dans les pays « riches ») la possibilité d’accéder à votre site.
Ne croyez pas que cette approche soit uniquement philantropique. Rappelons que Facebook et Twitter l’appliquent déjà avec les versions « Light » de leurs applis exemple : Facebook Lite.
Un site étant non seulement compatible sur mobile mais prenant en compte toutes les plateformes mobiles et toutes les vitesses de connexion devrait donc normalement être valorisé dans un futur proche par Google. D’autant plus que, plus le site sera léger, moins Google consommera de ressource.
Et comme pour l’utilisateur, la consommation et surtout l’impact sur l’environnement devient de plus en plus important:
- Obligation de rédiger des rapports de développement durable
- Pression des ONG pour réduire ses impacts, par exemple le rapport Greenpeace
Il est certain qu’un site efficient et répondant uniquement au besoin de l’utilisateur sera mieux valorisé dans le classement SEO de Google (et des autres).
Conclusion
Le référencement de votre site web par Google s’appuie en partie sur la notion de crawling : le robot parcourt les pages de votre site. Pour cette opération, il se fixe un budget de temps et de ressources. Si vos pages sont trop lourdes, trop lentes, le crawling ne sera réalisé que partiellement. Votre site sera mal référencé.
Pour éviter cela, commencez par prendre l’habitude d’évaluer la « crawlabilité » de votre site. Puis mettez en place une démarche de progrès. En première approche, regardez ce que vous pouvez obtenir à l’aide des outils de performance classiques.
Puis réfléchissez en termes de MobileFirst : appliquez les principes de l’écoconception à votre site. Simplifiez le parcours utilisateur, enlevez ou réduisez les fonctions inutiles. Mesurez votre consommation d’énergie et mettez-là sous contrôle.
Au prix de ces quelques efforts, vous obtiendrez un site mieux référencé, plus performant, apprécié des utilisateurs.
De nombreux sites web ayant cédé à l’obésité (trop de requêtes, des scripts superflus…), il est urgent d’anticiper l’évolution des algorithmes de référencement de Google, qui suivent désormais les mêmes objectifs que les utilisateurs, en demandant plus de performance ET moins de consommation d’énergie : en un mot, de l’efficience.
