Analyse statique de code dans une BDD orientée graphe
GREENSPECTOR permet de détecter des comportements des logiciels ayant un impact sur la consommation de ressources (énergie, mémoire….). Nous utilisons pour cela un ensemble de techniques permettant d’être le plus précis dans les constats pour permettre d’obtenir des gains importants et cela avec peu d’effort. L’analyse de code et la détection de patterns consommateurs fait partie de ces techniques.
Généralement, l’analyse de code se focalise à une détection syntaxique (c’est ce que l’on peut voir dans une IDE quand on tape du code et que l’IDE nous propose une autre écriture). Nous avons initialement utilisé ces techniques classiques d’analyse de code mais les résultats ne nous semblaient pas satisfaisants. En effet, nous obtenions trop de violations (le développeur pouvait être noyé dans trop de violations), et parfois des faux positifs. Au-delà de cela, de simples règles syntaxiques ne permettaient pas de détecter des règles poussées (ayant un impact sur la consommation de ressources) comme la détection des Wake lock sur Android. C’est la raison pour laquelle nous avons choisi de partir sur une autre technique d’analyse. Voici notre retour d’expérience.
Dès leur apparition dans les années 50, l’analyse du code source écrit dans un langage fut rapidement perçue comme un enjeu d’importance. En effet, LISP, un des tous premiers langages (1956) est par nature autoréférentiel et permet à un programme de s’analyser lui-même. Dès lors que l’ordinateur personnel s’imposa, il ne fallut qu’une dizaine d’années pour voir apparaitre des IDEs, comme Turbo Pascal de Borland, qui proposa de plus en plus de services d’assistance au programmeur. Pendant ce temps Emacs montrait la voie : analyse de code (grâce au LISP), code en couleur, etc…
L’analyse du code source lors de son écriture est maintenant partie intégrante de l’environnement de développement mis en place lors de l’initiation d’un projet : Jenkins, Eclipse propose des services sans cesse plus performants. GREENSPECTOR est l’un de ces assistants qui assiste le développeur à écrire une application plus efficiente en consommation énergétique.
Plonger dans les entrailles du code
GREENSPECTOR propose entre autre d’analyser le code source afin de trouver des formes, des façons d’écrire qui pourraient être améliorées en termes de performances d’exécution, de consommation mémoire ou de consommation réseau, trois facteurs ayant une forte incidence sur la consommation d’un smartphone, permettant à votre client de pouvoir profiter de celui-ci toute la journée.
Hello world de la détection de pattern
Prenons un exemple stupide mais simple.
Chacun reconnaitra qu’il est plus malin d’écrire :
var arraySize = myarray.length;
for (var i = 0 ; i < arraySize ; i++) {
aggr += myarray[i];
}que
for (var i = 0 ; i < myarray.length ; i++) {
aggr += myarray[i];
}Dans le second exemple, on aura un appel à la méthode length à chaque test de la boucle.
Dans un tableau de taille conséquente, cet appel de méthode peut vite devenir coûteux.
AST
Bien évidemment, on ne peut pas analyser le texte brut du code, mais une représentation de données adaptée à la manipulation par programmation.
On appelle cette représentation un AST, pour Abstract Syntax Tree.
Comme son nom l’indique, un AST est un arbre… On verra plus tard pourquoi c’est important.
L’AST de notre premier bout de code pourrait ressembler à quelque chose dans le genre :
VarDecla ("arraySize", MethodCall(VarRef "myarray","length",[]));;
For (VarDecla ("i", Lit "0"),
BinOp ("<", VarRef "i", VarRef "arraySize"),
UnOp ("++", VarRef "i"),
Block[BinOp ("+=", VarRef "aggr", ArrayAccess (VarRef "myarray", VarRef "i"))]
);;Obtenir cet AST n’est pas évident. En Java, on dispose de JDT, PDT pour respectivement Java et PHP. Ces librairies sont éprouvées, et même si leur fonctionnement est un peu difficile à appréhender et leur logique laisse parfois à désirer, elles restent assez efficaces.
Chez GREENSPECTOR, nous avons choisi d’utiliser Scala pour réaliser notre outil d’analyse de code. Scala, la puissance du fonctionnel, les avantages de la JVM.
Afin de réaliser des analyses sur l’AST, nous avons écrit notre propre grammaire en Scala, qui est un mapping des grammaires JDT ou PDT. Cette grammaire, utilisant les cases class de Scala, nous permet de bénéficier du pattern matching que ce langage a piqué à OCaml, lors de sa conception.
Ainsi, une affectation de variable est ainsi définie en Scala :
case class AssignmentJava ( id:Long, vRightHandSide : JavaExpression, vLeftHandSide : JavaExpression, vOperator : JavaAssignmentOp, lne : (Int,Int)) extends JavaExpressionTandis qu’un pattern-matching (sorte de switch-case au stéroïdes) sur cette structure ressemble à
case AssignmentJava( uid, vRightHandSide, vLeftHandSide, vOperator, lne) => ...A droite, on peut faire ce qu’on veut des variables uid, vRightHandSide, vLeftHandSide, vOperator, …
Cette façon de faire est très puissante pour analyser un arbre.
Détecter les boulettes
Maintenant que nous avons notre arbre, il va falloir détecter des problèmes qu’on voudrait remonter à l’utilisateur.
Problème, on ne sait toujours quel problème on va lui remonter. Donc écrire cette détection dans le programme en Scala, avec le pattern-matching n’est pas très flexible, car il faut sans-cesse changer le programme. De plus, ce n’est pas forcément simple à écrire.
En bon fainéant, nous voici à la recherche d’une méthode moins fastidieuse.
En fait, je vous ai menti : pour être fainéant, Scala et son pattern-matching n’est pas adapté. Or, qui dit simplicité, dit requête.
Eh bien voilà, il nous faut un langage de requête ! Comme SQL ou les regexp. Un truc où on décrit juste ce qu’on cherche, et paf, le système nous le ramène !
BDD Graphe
Heureusement, le monde sans cesse plus foisonnant de l’Open Source arrive à la rescousse : Neo4j est un serveur de base de données orienté graphe.
Même s’il est plus conçu pour analyser qui sont vos amis sur Facebook ou avec qui vous discutez sur Twittter, on peut l’utiliser pour une raison simple : un arbre est un cas particulier d’un graphe !
Mais surtout, Neo4j est doté d’un langage parfait pour un fainéant : Cypher.
Cypher est le langage de requête de Neo4j, il est totalement conçu pour trouver n’importe quoi dans un graphe.
D’où l’idée de mettre notre AST dans Neo4j et d’utiliser Cypher pour trouver ce que l’on cherche.
Trouver du code mal écrit
C’est souvent moins de 20% du code qui mobilise 80% du CPU la plupart du temps !
Un AST n’est juste qu’une représentation arborescente d’un texte, la densité d’informations sémantiques restant limitée. Afin de pouvoir analyser plus précisément le code et détecter des motifs intéressants et/ou difficiles à voir, on a besoin d’accroitre la densité sémantique du code. Pour se faire, on va transformer notre arbre en graphe, en créant des liens entre éléments de notre AST. Par exemple, nous allons pouvoir créer des liens entre des nœuds de type ‘Déclaration de fonction’, de sorte que l’on sache quelle fonction appelle quelle fonction. Bien évidemment, chacun de ces appels sera aussi relié à l’endroit où cette fonction est appelée.
On appelle cela le ‘Graphe d’Appel‘ notons que cette construction est plus aisée à faire dans certains langages que d’autres. Ainsi Java, de par sa structure et ses déclarations de type obligatoires nous permet de retrouver plus facilement le graphe d’appel que des langages comme, disons, au hasard, Javascript ou PHP 😉
La difficulté consiste à ne pas se tromper d’appel : combien de méthodes différentes vont s’appeler ‘read’ par exemple ? Potentiellement beaucoup. Il faut donc s’assurer que l’on relie bien les 2 bonnes fonctions, et pour se faire déterminer quel est le type de l’appelant, dans les langages orientés objet.
Connaitre le graphe d’appel, combiné à d’autres analyses, permet de savoir quel partie de code s’exécute le plus souvent, car on en a l’intuition, mais on ne le sait pas toujours, c’est souvent moins de 20% du code qui mobilise 80% du CPU la plupart du temps. En connaissant les parties du code les plus souvent exécutées, on pourra attirer l’attention du développeur sur des optimisations particulières à faire sur des portions critiques du code.
De même pour économiser de la mémoire, il faut utiliser plus intelligemment les variables que l’on déclare. En retrouvant leurs déclarations et les liens avec leur utilisation, on devient capable d’indiquer comment optimiser l’utilisation de la mémoire.
Illustrons ce que nous avons abordé avec un exemple simple, le helloworld de la détection de pattern. On observe souvent, en java, des boucles itérant simplement un tableau, en vérifiant que l’index est strictement inférieur à l’index du tableau. Cet exemple est améliorable, car l’appel à la méthode .size() est couteux et pourrait être mis « en cache » dans une variable.
for(int i=0; i < feeds.size(); i++) {
feedIds[i] = feeds.get(i).getId();
}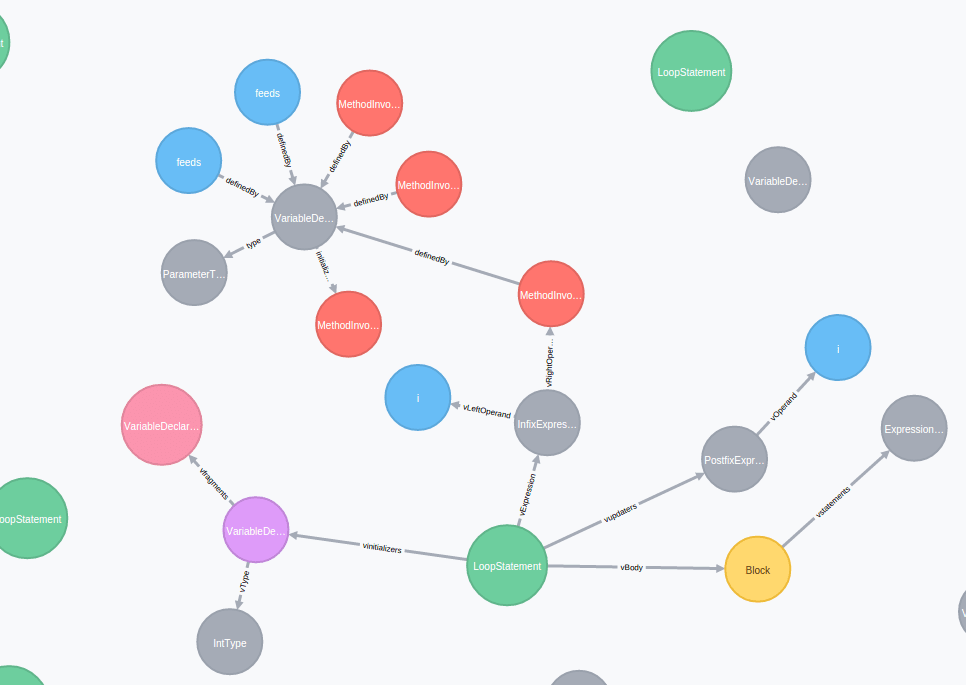
Le langage cypher dont nous avons parlé tout à l’heure nous permet de détecter à coup sûr ce genre de « forme » de code :
match (n:LoopStatement) where n.loopType = "ForStatementJava" with n match (n)-[:vExpression]->(i:InfixExpression)-[vRightOperand]->(m:MethodInvocation) where m.methodName = "size" return n;En gros, on lui demande de trouver un for classique en Java, ayant dans l’updater du for, un appel de méthode size()
Conclusion
La représentation sous forme de graphe modifiable offre une grande flexibilité pour l’analyse du code. Elle permet d’analyser le code avec la profondeur d’analyse choisie et d’améliorer sans cesse la qualité d’analyse du code.
Au sein de GREENSPECTOR, de par sa simplicité, sa puissance et son intuitivité, le langage de requête Cypher a vite été adopté et la montée en compétence fut rapide.
Nos règles sont maintenant beaucoup plus cohérentes et avec moins de faux positifs. A vous de le découvrir en lançant une analyse de code avec GREENSPECTOR !
De notre côté, il nous reste encore à explorer toutes les possibilités de cette architecture qui nous permettra à terme de réaliser des analyses de haut niveau.

Expert Sobriété Numérique
Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», …
Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …)
Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels