Qui n’a jamais utilisé DeepSeek, ChatGPT, Copilot, Gemini, Mistral… ? Les LLMs (Large Language Models) deviennent des incontournables de la vie de tous les jours dans nos vies professionnelles ou personnelles.
Comme le précise l’étude de Deloitte, ces IA génératives ont un impact environnemental et énergétique élevé, notamment côté serveur. Elles représentent aujourd’hui 1.4% de la consommation d’électricité mondiale et devrait tripler d’ici 2030. Les modèles étant très lourds, ils consomment beaucoup lors du traitement de la donnée et la génération de la réponse. Une autre analyse de McKinsey publiée en octobre 2024, estime que la demande en capacité de datacenters adaptés à l’IA augmentera en moyenne de 33% par an entre 2023 et 2030.
Dans le cas d’une IA générative LLM, la consommation est élevée côté serveur mais il paraît intéressant de mesurer aussi la consommation et l’impact environnemental côté terminal utilisateur.
Récemment, DeepSeek a fait une entrée fracassante dans le milieu des LLMs en vantant des performances semblables aux meilleurs avec un modèle plus léger, donc moins consommateur côté serveur. Mais qu’en est-il côté client ? Nous proposons donc de mesurer et comparer sur la base d’un même parcours les performances des applications DeepSeek et ChatGPT.
Toutes ces mesures ont été réalisées sur terminal réel, ici un Samsung Galaxy S10 sur Android 12. Un tel modèle correspond à un smartphone d’entrée de gamme aujourd’hui.
Ces mesures ont été réalisées sur :
La versions 1.0.8 de DeepSeek
La version 1.2025.028 de ChatGPT.
c. Méthodologie et parcours
Pour mesurer les deux applications, nous avons utilisé un scénario utilisateur commun pour les 2 applications testées :
Ouverture de l’application
Connexion à un compte
Rédaction d’un premier prompt dit « prompt simple » : « Je suis à la recherche d’un stage dans le numérique responsable. Explique-moi en une phrase ce que c’est. »
Attente de la réponse au prompt simple
Rédaction d’un second prompt demandant une réponse de 500 mots dit « prompt 500 mots » : « A présent rentre dans le détail en développant ce qu’est le numérique responsable en 500 mots sans chercher sur le web. »
Attente de la réponse au prompt 500 mots
Activation de la fonction recherche sur internet
Rédaction d’un troisième prompt demandant la même chose que le prompt 500 mots mais en cherchant sur le web, « prompt web » : « A présent rentre dans le détail en développant ce qu’est le numérique responsable en 500 mots en cherchant sur le web. »
Attente de la réponse au prompt web
Téléchargement d’un CV sur internet
Insertion d’un fichier dans le LLM
A noter que ces différents prompts s’enchaînent dans une seule et même discussion.
Note méthodologique complémentaire :
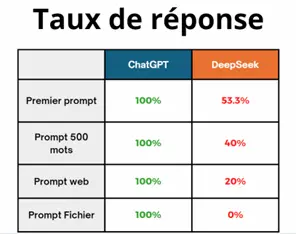
Nous avons intégré uniquement les mesures qui fonctionnellement présentent un résultat. Il a été fréquent au cours des mesures que DeepSeek ne réponde pas à la demande de l’utilisateur, probablement, par cause de serveurs trop chargés. Il a donc fallu réaliser plus de mesures sur DeepSeek pour avoir des résultats exploitables. Nous avons également supprimé une partie du parcours initialement testé à partir de la réponse au prompt fichier car DeepSeek n’a pas fourni de réponse sur la génération d’une lettre de motivation.
I. Performances, consommations et impacts environnementaux
a. Place occupée par l’application sur le smartphone
Les applications ne font pas le même poids, DeepSeek fait 32.3 Mo contre 76.4 Mo pour ChatGPT donc plus de deux fois le poids de son concurrent. Même constat pour les fichiers APKs, ceux de DeepSeek sont deux fois plus légers que ceux de ChatGPT.
Compte tenu du nombre d’installations et le nombre de mises à jour de ces 2 applications, ceci n’est pas négligeable dans l’impact généré par ce prérequis d’usage. On parle ici de plus de 10 millions de téléchargement sur le playstore pour DeepSeek et plus de 100 millions pour ChatGPT.
b. Vitesse de décharge
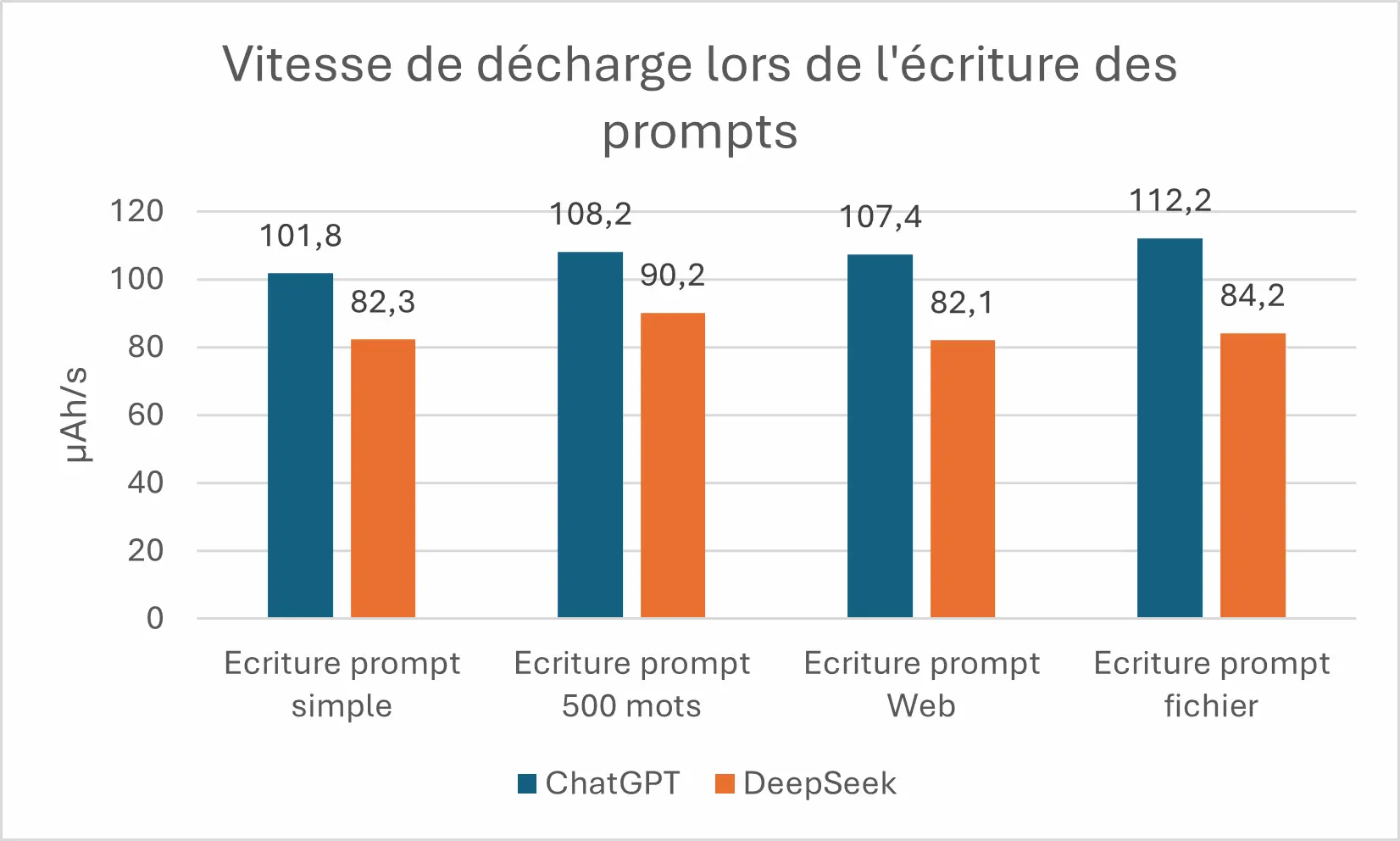
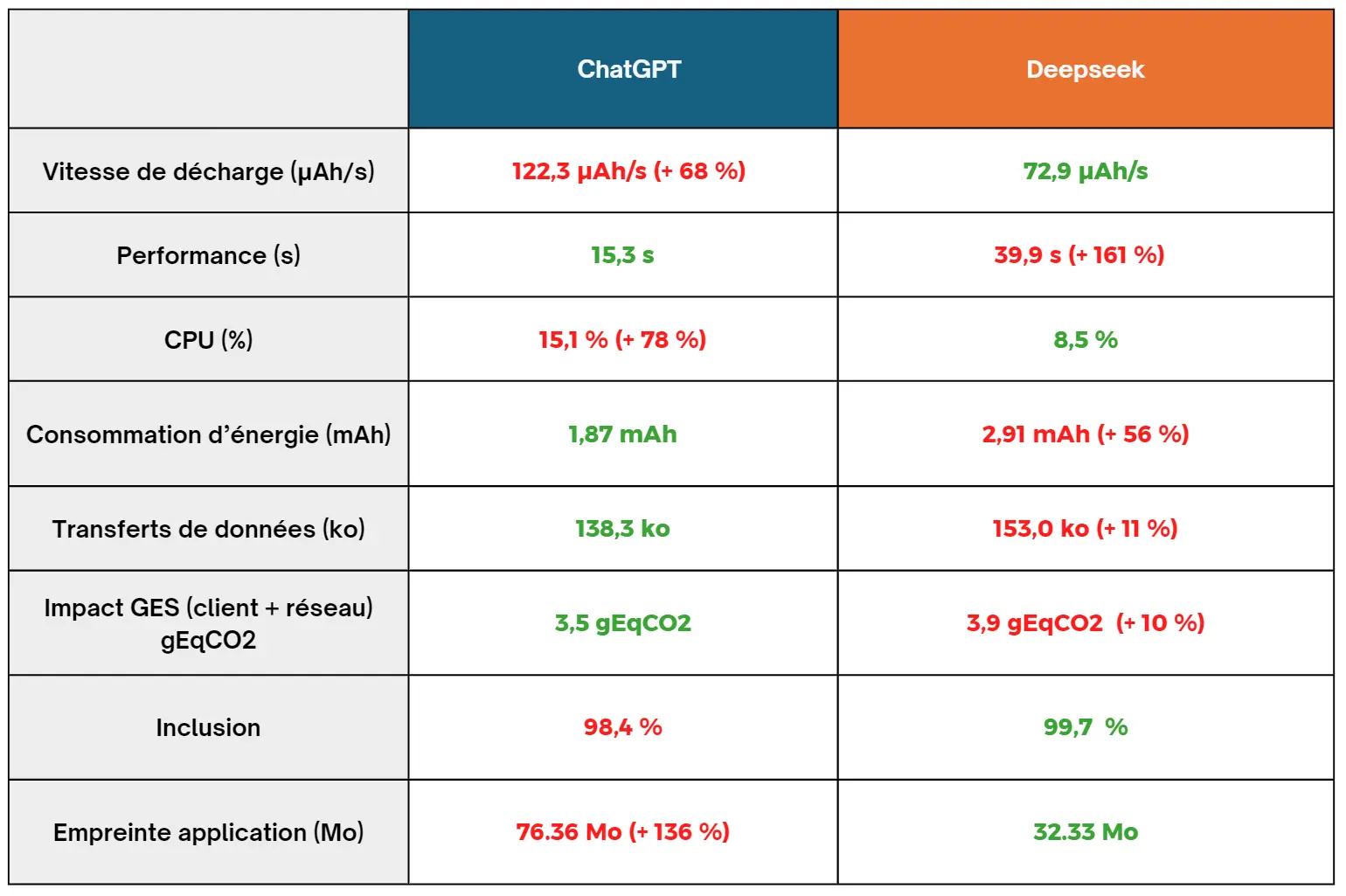
ChatGPT décharge la batterie plus vite lors de l’écriture d’un prompt. 101.8 µAh/s contre 82.3 µAh/s pour DeepSeek, chiffres venants du prompt simple. C’est une tendance qui se vérifie sur tous les prompts. Etant donné que l’écriture des prompts prend autant de temps pour l’un comme pour l’autre, en moyenne, DeepSeek consomme 24 % moins que ChatGPT sur l’écriture des prompts.
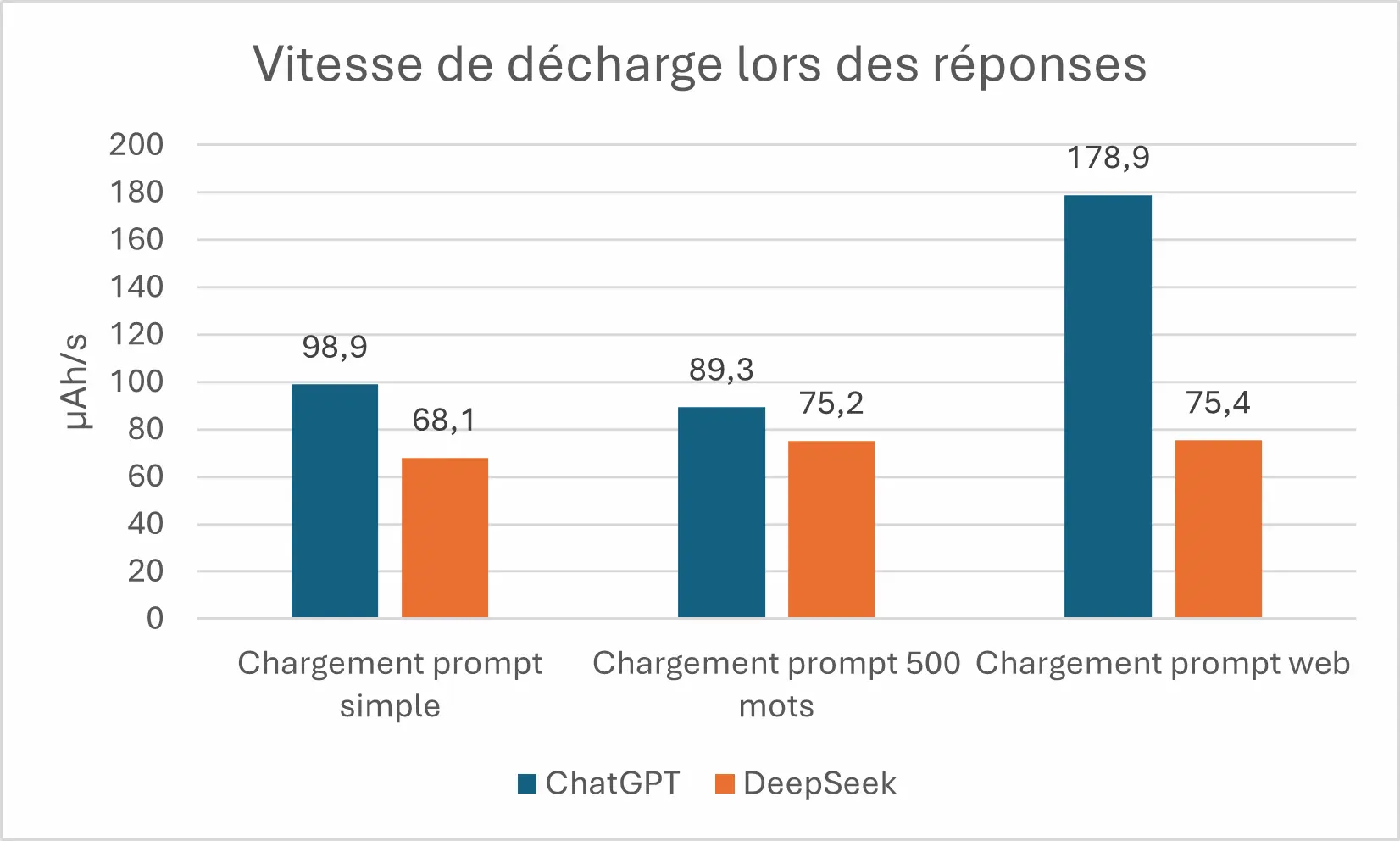
DeepSeek décharge moins vite le smartphone que ChatGPT lors de l’utilisation de l’application. Cela se confirme également dans la réponse des prompts où en moyenne DeepSeek décharge 67 % moins vite le smartphone que ChatGPT.
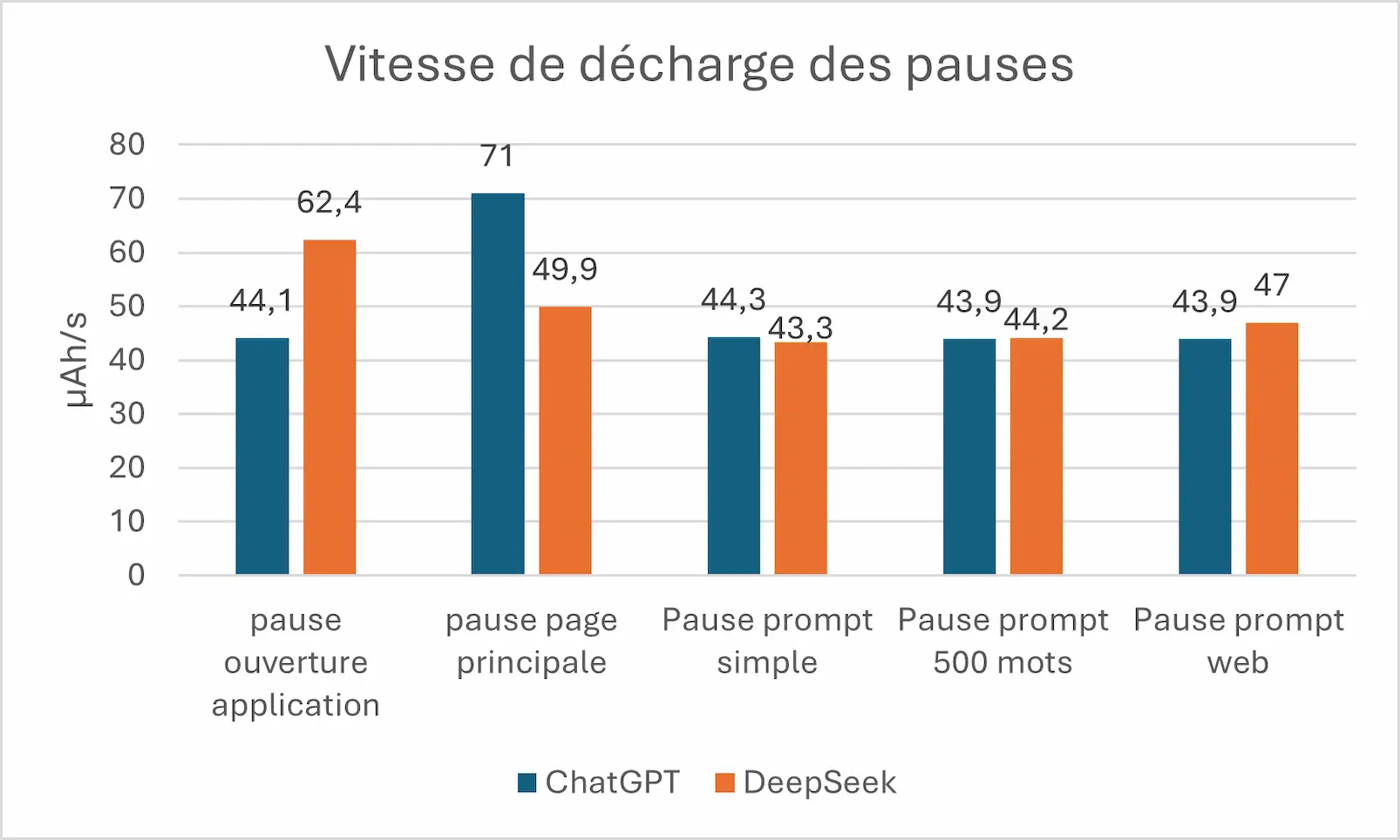
Comme souvent, que ce soit une application web ou mobile, une des pages les plus consommatrices est la page/écran d’accueil ou du moins la page principale. On peut le constater avec le tableau ci-dessus, lors de l’ouverture de l’application, DeepSeek consomme environ 42% plus que ChatGPT. Cependant une fois arrivé sur la page principale, ChatGPT consomme à son tour 42% plus que DeepSeek.
Sur les autres pauses, il y a une variation entre 2% et 7% en faveur de l’un ou de l’autre, donc pas de différence significative là-dessus.
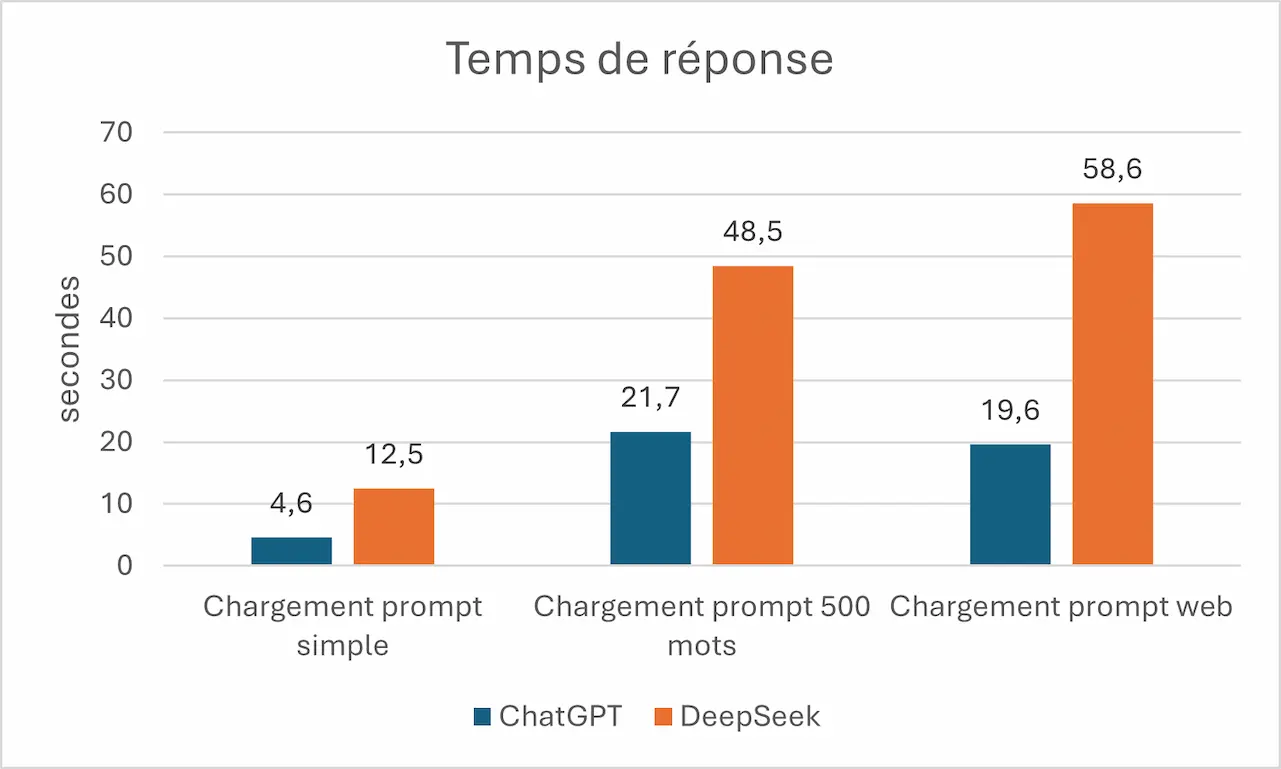
c. Temps de réponse
Sur les deux applications le temps de réponse pour un même prompt varie grandement d’une itération à l’autre. Par exemple sur ChatGPT, les mesures vont de 14.2s à 44.7s pour le chargement du prompt web. DeepSeek, lui, prend entre 48.7s à 1m10s pour le même prompt. De façon générale, ChatGPT est plus rapide pour répondre de façon significative, que ce soit pour un prompt simple ou à plus de 500 mots, ChatGPT répond au moins deux fois plus vite pour un prompt simple. On peut donc poser le constat qu’en moyenne ChatGPT répond en moyenne sur nos cas d’usage 2.5 fois plus vite que DeepSeek
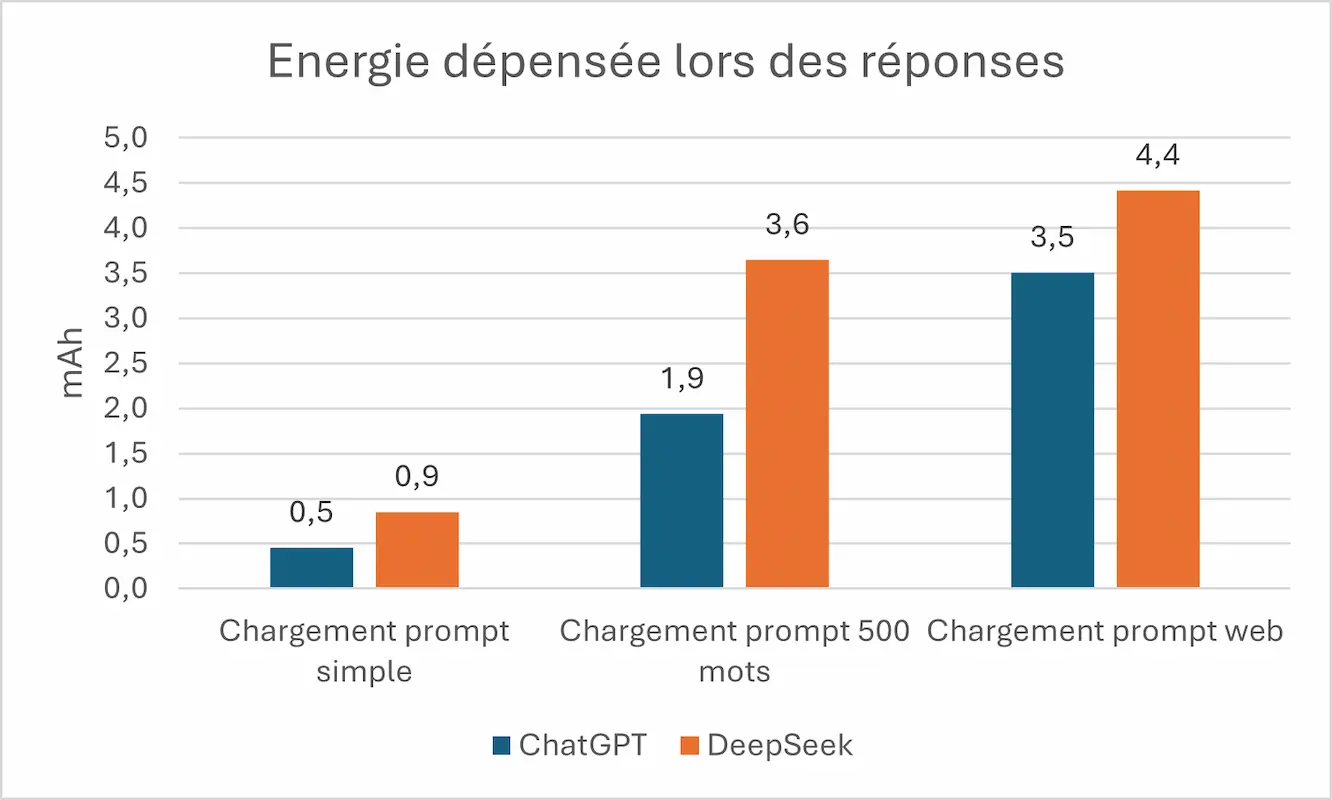
d. Énergie consommée
Au vu du temps de réponse et la vitesse de déchargement, on en déduit le tableau ci-dessus qui nous indique qu’en énergie pure, ChatGPT consomme moins même s’il consomme largement plus par unité de temps. En effet, les temps de réponses étant significativement à son avantage, ChatGPT en tire profit pour dépenser moins d’énergie que DeepSeek sur l’ensemble du parcours sur le device utilisateur, soit en moyenne 34 % de moins que DeepSeek.
e. Données échangées sur le réseau
ChatGPT a un flux de données nul avec les serveurs lors de l’écriture du premier prompt d’une discussion. Par la suite il échange plusieurs kilooctets avec les serveurs sur les prompts à 500 mots et ceux pour le fichier. Enfin, il est particulièrement « datavore » lors de la rédaction du prompt web en allant jusqu’à 62 ko. DeepSeek quant à lui, n’échange que quelques kilooctets (5.2 ko) lors du premier prompt et par la suite, il échange beaucoup moins de données avec les serveurs que ChatGPT, en moyenne 90% de moins.
On peut constater des mesures ci-dessus que de manière générale, DeepSeek utilise plus de données pour répondre que ChatGPT. L’IA chinoise a tendance à rédiger des réponses plus longues que ChatGPT pour la même question. L’exception concerne le prompt web pour lequel ChatGPT échange plus de données.
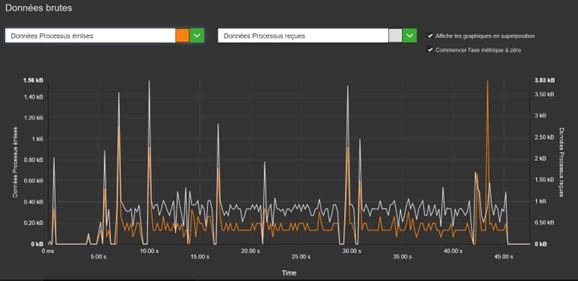
Quand on analyse un peu plus finement la manière dont les données transitent pendant la réception d’une réponse, on peut constater en voyant le graphique ci-dessus que plusieurs paquets arrivent au fur et à mesure de la réponse, au fur et à mesure qu’elle s’affiche. A chaque réception de paquet, l’application en émet un à son tour pour confirmer la réception de ce-dernier. Ceci sollicite à fréquence régulière la cellule radio du smartphone et des mécanismes de mise à jour dans la page de réponse qui vont occasionner une consommation d’énergie importante. En étudiant les fichiers JSON des paquets reçus, on peut constater que les JSON de ChatGPT sont beaucoup moins lourds, en raison d’une taille de Token plus élevée. Chaque Token ChatGPT contient jusqu’à 42 caractères contre seulement 5 caractères maximum pour DeepSeek.
Du côté de DeepSeek, le lancement de l’application demande plus de données que ChatGPT. Pour autant, une fois l’application définitivement lancée, Il n’y a plus que de légers flux de données “raisonnables”. ChatGPT est beaucoup plus gourmand en termes de données échangées. Il a une consommation moindre lors de l’ouverture de l’application mais ensuite lors de chaque pause (affichage sans interaction) qui succède à une réponse, il y a un flux « anormalement » élevé pour une étape de pause.
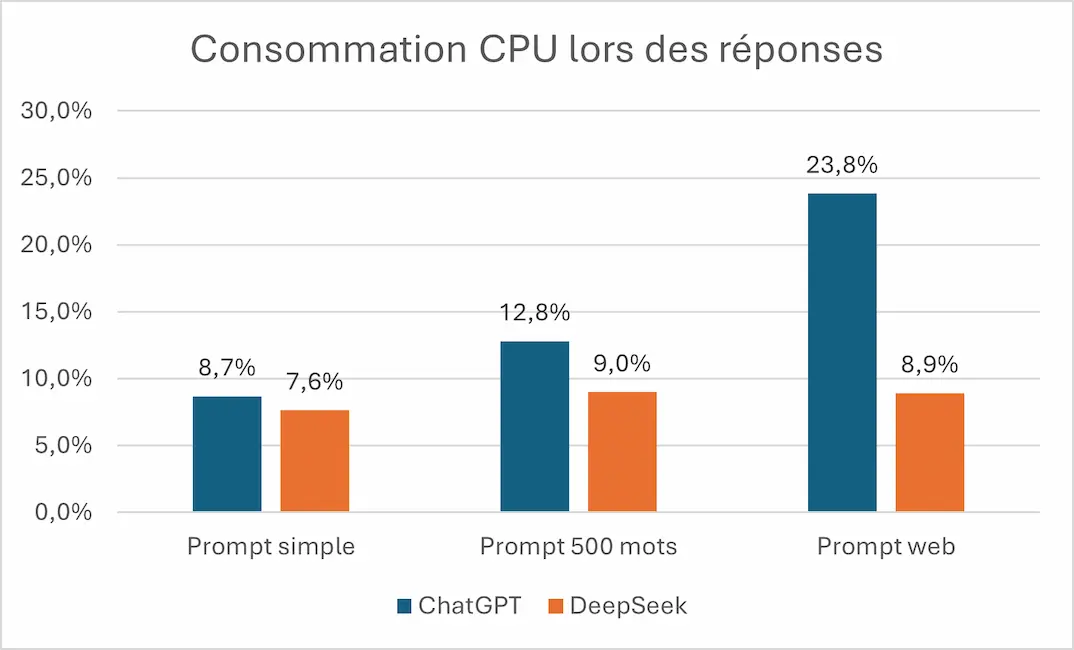
f. CPU
On a remarqué que DeepSeek décharge moins vite sa batterie que ChatGPT, et de manière cohérente on constate qu’il consomme moins de CPU également. Comme on peut le voir sur le graphique ci-dessus pour chaque réponse, ChatGPT est plus exigeant en CPU que DeepSeek, avec notamment une différence très importante sur le prompt web avec 23.8% de la CPU utilisée par ChatGPT alors que pour la même action DeepSeek n’en utilise que 8.9%. Pourtant ChatGPT utilise cette CPU pendant moins de temps, ce qui nous permet de faire la même conclusion que l’énergie, ChatGPT est plus exigeant en termes de CPU par unité de temps mais sur l’ensemble de la réponse il consomme moins de CPU que DeepSeek.
En projetant ces métriques de flux sur un périmètre ne tenant pas compte de l’impact côté Datacenter mais uniquement de l’impact réseau et du poste client, on obtient les données suivantes :
Impacts de parcours unitaires :
Comme on peut le constater, l’impact environnemental est à l’avantage de ChatGPT (10 %). Cependant que ce soit pour l’un ou pour l’autre l’impact reste très élevé pour seulement trois réponses, plus d’un gramme de CO2 par réponse en moyenne. Cela correspond environ à une vidéo de 2 minutes pour ChatGPT et de 2 minutes 30 secondes pour DeepSeek.
Impacts environnementaux quotidiens sur smartphone
Pour autant, à grande échelle, ChatGPT reste significativement moins impactant. Par exemple pour 100 millions d’utilisation donc 300 millions de réponses, DeepSeek a un impact supérieur de 40 tonnes EqCO2 côté client. Les consommations restent très importantes pour les deux solutions, en sachant que d’après OpenAI, ChatGPT reçoit 1 milliard de requêtes par jour, dont 48% sur mobile, ChatGPT consomme donc en moyenne, uniquement du côté smartphone, 560 tCO2e par jour.
II. Accessibilité et discrétion
a. Accessibilité et inclusion
De manière visuelle les deux applications sont semblables, les boutons font la même taille, les écrans sont disposés de la même manière. On peut leur reprocher des contrastes parfois trop peu marqués et des zones de clics parfois trop petites. La différence se fait au niveau de l’accessibilité pour mal-voyant ou non-voyant. En effet lors de l’automatisation, nous avons pu constater que les différents éléments du layout de DeepSeek ne possèdent pas à cette heure de description, d’identifiant ou de tout élément qui nous permet de les distinguer à la lecture de la page. Au-delà de rendre l’automatisation de l’application plus compliquée, c’est surtout un problème pour les personnes atteintes de handicap visuel. En effet, leurs logiciels d’assistance s’appuient sur ces contenus pour avoir une description de la page et pouvoir utiliser ces applications. C’est une mauvaise pratique à bannir pour permettre l’inclusion du plus grand nombre. Concernant l’inclusion des anciennes versions d’Android, DeepSeek demande au moins la version 5.0 d’Android qui concerne donc 99.7% des usagers potentiels au niveau mondial et ChatGPT demande la version 6.0 d’Android soit un accès pour 98.4% des usagers potentiels. Question accessibilité, DeepSeek est moins lourd et disponible pour quelques usages de plus que ChatGPT mais pose un gros problème pour les non-voyants.
b. Autorisations suspectes
Les applications du smartphone requièrent des autorisations pour mener à bien leur usage avec des fonctionnalités utilisant la caméra et le microphone du terminal, ce qui justifie l’attribution de ces permissions. De façon plus étonnante, ChatGPT demande un accès à la localisation, les contacts ou même le calendrier. En explorant les fichiers APKs de l’application, on peut constater qu’il détecte également la prise de screenshots (quand l’application est ouverte) et qu’il demande aussi accès à la connexion bluetooth. DeepSeek est quant à lui plus raisonnable, à part la caméra et le microphone, il ne demande pas de permission supplémentaire.
Conclusion
Comme on a pu le voir tout au cours de notre analyse, DeepSeek décharge moins rapidement la batterie, utilise moins de CPU par unité de temps et fait transiter moins de données mais a des temps de réponse largement plus élevés. Ces temps de réponses sont la cause principale d’une dépense énergétique plus importante que ChatGPT sur l’ensemble du parcours. Le manque d’accessibilité de DeepSeek pour les non-voyants est clairement un problème pour son utilisation. Sur le cas d’usage observé, il est clair que l’impact environnemental de l’IA est plus important côté serveur. Pour donner un ordre de grandeur, la valeur pour ChatGPT pour le parcours réalisé est de 45,48 gEqCO2, d’après le site Ecologits alors que côté terminaux utilisateur, elle est seulement de 3.5 gEqCO2, soit 8 % de la consommation. On peut en déduire que sur un parcours unitaire côté terminal utilisateur (et réseau), ChatGPT a un impact environnemental plus faible que DeepSeek en émission de gaz à effet de serre. Cet impact plus faible s’explique par sa consommation d’énergie plus faible, cependant l’évolution des temps de réponses de DeepSeek est à surveiller car si l’application de la baleine bleue s’améliore sur ce point-là, elle pourra aisément devenir moins consommatrice que ChatGPT et moins impactant en terme environnemental sur le terminal client.
Bientôt notre offre Greenspector Studio SaaS Self-service pour tester et vous lancer dans un premier abonnement de manière autonome au service. Restez informés de la sortie sur Product Hunt
Imaginez un assistant virtuel capable de rédiger un courriel, traduire un texte ou résoudre une équation complexe, directement depuis votre téléphone, sans jamais envoyer vos données sur internet. C’est la promesse des IA locales comme Apple Intelligence, Gemini Nano ou Galaxy AI. Ces modèles offrent des avantages indéniables en matière de latence et de respect de la vie privée, mais à quel prix ?
Exécuter ces algorithmes directement sur votre appareil exige des ressources matérielles conséquentes et entraîne une consommation énergétique non négligeable. Cette intensité de calcul impacte non seulement l’autonomie de votre batterie, mais aussi la durée de vie du parc de smartphones existants. Faut-il alors s’inquiéter de l’essor des IA locales, plus encore que des IA basées sur serveur ?
Cet article se concentre sur l’impact énergétique des IA locales sur nos smartphones pour un cas d’usage précis. Il sera suivi d’analyses complémentaires sur d’autres usages, comme la génération de texte ou le traitement d’audio et d’image (détection d’objets, segmentation d’image, reconnaissance vocale…).
À l’aide de Greenspector Studio, nous avons mesuré, pour différents grands modèles linguistiques locaux et distants, la durée et l’énergie consommée pour générer une réponse. L’objectif ? Quantifier l’impact réel de ce forcing technologique1 sur nos batteries.
Méthodologie
Contexte de mesure
Samsung Galaxy S10, Android 12
Réseau : off pour modèle local / Wi-Fi pour ChatGPT et Gemini
Luminosité : 50 %
Tests réalisés sur minimum 5 itérations pour fiabiliser les résultats
Pour chaque test, une nouvelle conversation a été initiée, puis 5 questions (appelées prompt) ont été posées au modèle :
You’re an expert in digital eco-design. All your answers will be 300 characters long. What are the three fundamental principles for optimizing performance data consumption and energy in Android applications?
Develop the first principle
Develop the second principle
Develop the third principle
Conclude our exchange
Temps de réponse
L’un des facteurs déterminants pour l’expérience utilisateur est le temps de réponse. En plus de cela, notre smartphone ne pourra pas se mettre en veille, et donc économiser de l’énergie, pendant la génération de la réponse. Nous avons pu mesurer ce temps de génération de réponse, du moment où on envoie le prompt, jusqu’au dernier caractère de la réponse. Voici les résultats obtenus pour les trois modèles étudiés :
Modèles locaux
Modèles
Nombre de paramètres du modèle
Durée de réponse moyenne (s)
Durée totale de réponse (s)
Llama 3.2
1,24 milliard
25,9
129,5
Gemma 2
2,61 milliards
37,9
189,5
Qwen 2.5
7,62 milliards
54,2
271
Comparaison des Performances de Modèles d’IA Locaux : Paramètres, Temps de Réponse moyen et Durée Totale de Réponse
Ces données mettent en évidence une tendance claire : plus le modèle contient de paramètres, plus le temps nécessaire pour générer une réponse est long. Par exemple, le modèle Llama 3.2, avec ses 1,24 milliard de paramètres, offre une réponse en moyenne en 25,9 secondes. En revanche, Qwen 2.5, beaucoup plus volumineux avec 7,62 milliards de paramètres, affiche une durée moyenne de 54,2 secondes, soit plus du double.
Modèles distants
Si les modèles d’intelligence artificielle locaux présentent des avantages notables, notamment en matière de protection de la vie privée, leur rapidité est nettement moins impressionnante lorsqu’on les compare aux modèles déployés sur des serveurs distants :
Modèles
Durée de réponse moyenne (s)
Durée totale de réponse (s)
Gemini
4,97
24,85
ChatGPT
5,9
29,5
Comparaison des Performances de Modèles d’IA Distants : Temps de Réponsemoyen et Durée Totale de Réponse
Les résultats montrent une supériorité évidente des modèles distants en termes de rapidité. Par exemple, ChatGPT, hébergé sur des serveurs optimisés, délivre une réponse en moyenne en seulement 5,9 secondes, soit plus de quatre fois plus rapidement que Llama 3.2, le plus rapide des modèles locaux testés. De son côté, Gemini, avec une durée moyenne de réponse de 4,97 secondes, confirme cette tendance.
Cette différence ne se limite pas au temps de réponse. En plus de solliciter plus longtemps notre appareil, et donc retarder le retour à la veille, l’exécution locale des modèles d’IA impacte également la consommation énergétique des appareils. Ces temps de réponse laissent penser que la génération de réponse place le terminal sous une charge de travail intense, et donc une décharge de batterie élevée. Pour mieux comprendre cet impact, nous avons mesuré la vitesse de décharge de la batterie lors de la réponse des modèles.
Vitesse de décharge de la batterie
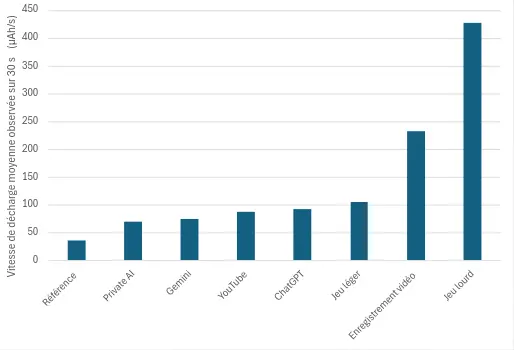
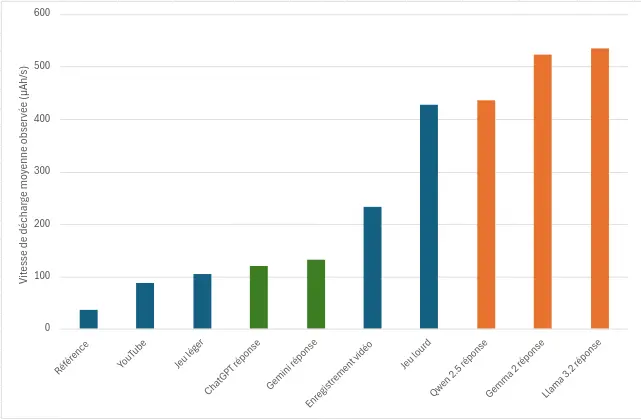
Pour référence, un Samsung Galaxy S10, avec la luminosité à 50 %, sans wifi et avec un fond d’écran noir affiché à l’écran, consomme autour de 36 µAh/s. Nous avons mesuré d’autres cas d’usages afin d’avoir des équivalences. Le Galaxy S10 est équipé d’une batterie de 3 400 mAh.
Vitesse de décharge moyenne observée sur 30 s (µAh/s)
Référence
36
Application Private AI ouverte, sans interaction
70
Application Gemini ouverte, sans interaction
75
Visionnage d’une vidéo sur YouTube sans son (Crabe Rave)
88
Application ChatGPT ouverte, sans interaction
92
Jeu léger (Subway Surfers)
105
Enregistrement vidéo
233
Jeu lourd (benchmark Wild Life de 3DMARK)
427
Décharge de la Batterie sur un Samsung Galaxy S10 : Comparaison Selon les Usages
Décharge de la Batterie sur un Samsung Galaxy S10 : Comparaison Selon les Usages
On observe ici que l’application ChatGPT est légèrement plus consommatrice que les autres applications d’IA, et est même plus consommatrice que YouTube. Les usages les plus consommateurs sont l’enregistrement vidéo et notre benchmark Wild Life de 3DMARK, qui reflète les jeux mobiles basés sur de courtes périodes d’activité intense, avec une résolution de 2560×1440.
Modèles locaux
L’exécution des modèles d’intelligence artificielle directement sur un smartphone n’est pas seulement une question de rapidité, elle soulève également des questions au sujet de la consommation énergétique. Les tests réalisés montrent que les modèles locaux consomment une quantité non négligeable d’énergie, influençant directement l’autonomie des appareils, et indirectement leur durée de vie. Voici les résultats observés lors de la génération de réponses :
Modèles
Vitesse de décharge moyenne observée (µAh/s)
Décharge de la batterie (mAh)
Durée totale de réponse (s)
Llama 3.2
535
69,3
129,5
Gemma 2
522
99
189,5
Qwen 2.5
435
118,1
271
Comparaison des Performances de Modèles d’IA Locaux : Vitesse de Décharge de la Batterie, Décharge de la Batterie et Durée Totale de Réponse
Ces chiffres révèlent une tendance intéressante : bien que le modèle Qwen 2.5 soit le plus gourmand en termes de nombre de paramètres (7,62 milliards), il présente une vitesse de décharge moyenne plus faible (435 µAh/s) que les modèles Llama 3.2 (535 µAh/s) et Gemma 2 (522 µAh/s). Cependant, sa décharge totale de batterie sur un parcours reste la plus élevée avec 118,1 mAh, en raison de la durée de traitement plus longue. Du point de vue de la batterie, utiliser un modèle local est au moins aussi consommateur que faire le benchmark Wild Life de 3DMARK.
Avec sa consommation de référence (terminal allumé, fond d’écran noir, luminosité à 50%, sans Wifi), on estime que la batterie de notre téléphone se décharge totalement en plus de 26h. En utilisant ces modèles, elle se décharge en 2h10 en utilisant Qwen 2.5 (soit environ 143 réponses), ce qui divisera votre autonomie par 12, 1h48 avec Gemma 2 (soit environ 171 réponses), ce qui divisera votre autonomie par plus de 14 et 1h45 avec Llama 3.2 (soit environ 245 réponses), ce qui divisera votre autonomie par 15. L’utilisation d’un grand modèle linguistique en local réduira donc l’autonomie de votre smartphone d’un facteur compris entre 12 et 15.
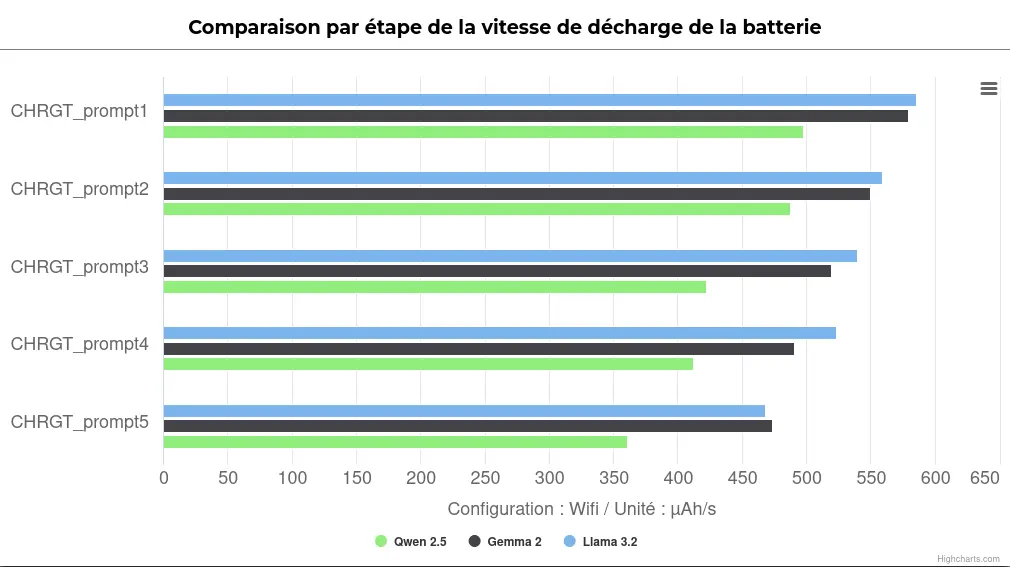
Lorsqu’on observe les vitesses de décharge des différents prompts on observe que cette dernière diminue au fur et à mesures des prompts. Ici, plusieurs explications sont possibles, telles que des optimisations logicielles ou des limitations matérielles. Toutefois, en l’absence de davantage de mesures, il est difficile d’affirmer avec certitude la cause exacte de ce phénomène. Nous reviendrons sur ces hypothèses dans le prochain article.
Comparaison par Etape de la Vitesse de Décharge de la Batterie pour les Modèles Locaux
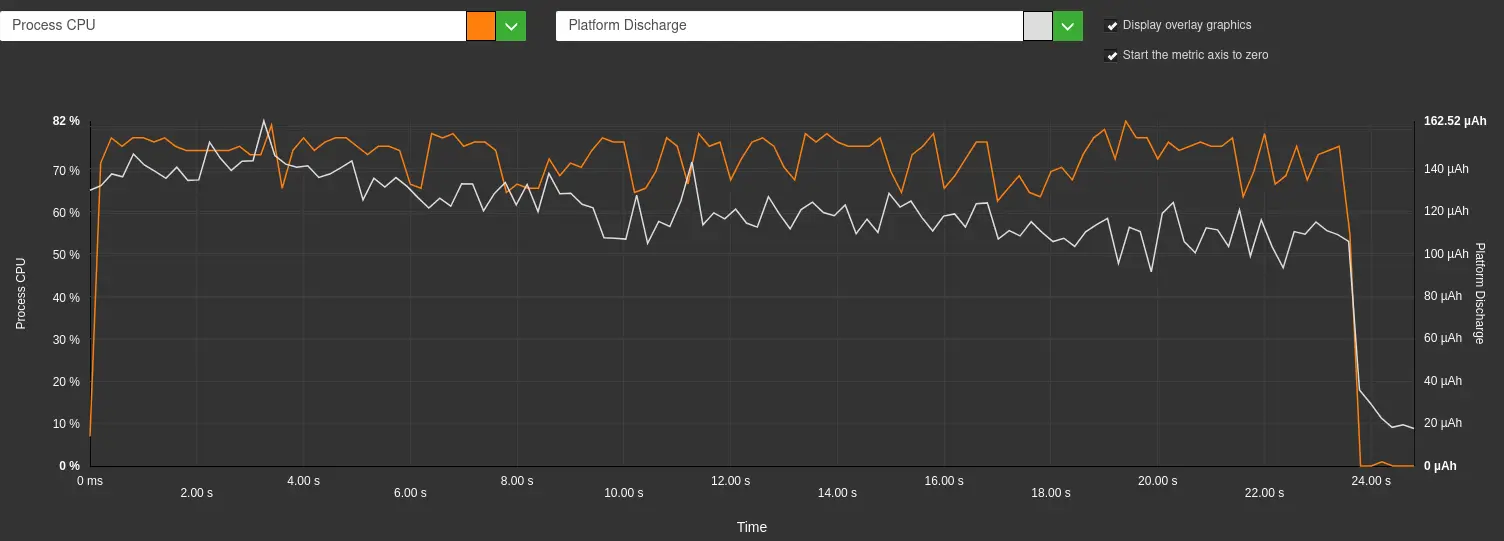
Cette forte décharge de la batterie est corrélée avec une très grande utilisation du CPU, comme nous pouvons le voir sur le graphique ci-dessous.
Décharge de la Batterie (blanc) et utilisation du CPU (orange) sur un Samsung Galaxy S10 pour une réponse de Llama 3.2 – Greenspector Atelier de Mesure
Modèles distants
Cet impact sur la batterie est d’autant plus significatif quand on le compare avec des modèles sur le cloud :
Modèles
Vitesse de décharge moyenne observée (µAh/s)
Décharge de la batterie (mAh)
Durée totale de réponse (s)
Gemini
132
3,2
24,85
ChatGPT
120
3,3
29,5
Comparaison des Performances de Modèles d’IA Distants : Vitesse de Décharge de la Batterie, Décharge de la Batterie et Durée Totale de Réponse
On observe que pour notre parcours, utiliser un modèle distant décharge notre batterie entre 21 et 37 fois moins qu’un modèle local. On pourra alors charger plus de 5170 réponses de Gemini (soit 7h7min) ou 4789 réponses de ChatGPT (soit 7h51min) avec une batterie complète.
Interroger un modèle local consomme 29 fois plus de batterie qu’interroger ChatGPT, un modèle distant.
Décharge de la Batterie sur un Samsung Galaxy S10 : Comparaison Selon les Usages
Le graphique ci-dessus met en évidence une distinction claire entre les modèles d’IA distants (en vert) et les modèles locaux (en orange) en termes de consommation énergétique. Observation surprenante, les modèles distants consomment tout de même plus d’énergie que le visionnage d’une vidéo YouTube ou qu’un jeu léger, alors même qu’ils ne transmettent qu’une faible quantité de données et n’exigent qu’un calcul minimal côté appareil, en dehors de l’affichage progressif du texte. En revanche, les modèles locaux présentent une consommation énergétique nettement supérieure, dépassant celle de tous les autres usages testés, y compris les tâches intensives comme les jeux lourds ou l’enregistrement de vidéos.
Ces résultats soulignent l’impact énergétique important des modèles d’IA exécutés en local sur les smartphones, posant un véritable défi pour l’autonomie des appareils ainsi que la durée de vie de la batterie dans un contexte d’utilisation prolongé et récurent.
Conclusion
Comme nous l’avons démontré, le gain en matière de vie privée offert par les modèles d’IA locaux s’accompagne d’un impact significatif sur la consommation d’énergie, en raison d’une sollicitation intense du CPU de nos smartphones. Conçus pour fonctionner en arrière-plan sans intervention explicite de l’utilisateur (réponses automatiques, résumés de mails, traductions, etc.), ces modèles mobilisent en permanence les ressources de l’appareil, accélérant ainsi la décharge de la batterie. Or, les batteries étant des composants consommables capables d’endurer entre 500 et 1 000 cycles de charge et décharge complètes2, cette surconsommation énergétique entraîne une usure prématurée. À terme, l’impact écologique est notable : remplacement du terminal ou de sa batterie plus fréquent.
Nous avons conscience qu’exécuter un grand modèle linguistique (LLM) en local n’est pas un cas d’usage réaliste à grande échelle. Toutefois, la tendance adoptée par les constructeurs et éditeurs de systèmes d’exploitation nous interpelle. Face aux nouvelles demandes en IA locale, ils cherchent à compenser les limites actuelles en augmentant la puissance de calcul des terminaux avec des accélérateurs dédiés et des batteries de plus grande capacité. Or, les temps de latence observés sur des appareils standards du marché, souvent jugés « inconfortables » pour l’utilisateur final, risquent de précipiter le renouvellement des smartphones vers des modèles plus performants. Une évolution qui pourrait accroître l’impact environnemental lié à la fabrication de nouveaux terminaux.
Nos premières mesures indiquent ainsi que l’intégration des IA locales ne fait que déplacer l’empreinte énergétique des serveurs vers les appareils utilisateurs, avec des conséquences environnementales potentiellement plus lourdes que celles des IA exécutées sur le cloud.
Dans la prochaine partie, nous explorerons les moyens de réduire l’impact énergétique de ces modèles en comparant différentes configurations matérielles (présence d’un accélérateur dédié, optimisation des architectures) et logicielles. Pour les développeurs et fabricants, le défi sera de trouver un équilibre entre puissance, rapidité et efficacité énergétique. L’optimisation des algorithmes, afin de minimiser leur consommation sans compromettre la qualité des réponses, pourrait être la clé pour rendre ces technologies viables à grande échelle.
Alors qu’un Français sur trois considère une batterie déchargée comme une véritable phobie3, sommes-nous prêts à sacrifier notre autonomie, accélérer l’usure de nos batteries ou changer prématurément de smartphone alors que notre appareil est encore fonctionnel – tout cela au nom du confort et de la vie privée ?
Pour aller plus loin …
Pour plus d’informations sur l’IA et son fonctionnement nous vous recommandons https://framamia.org/ . Pour plus d’information sur l’IA frugale nous vous recommandons les ressources disponibles ici : https://ia-frugale.org/
Consultant en numérique responsable, j’analyse l’impact environnemental des solutions numériques des entreprises.
Greenspector may use cookies to improve your experience. We are careful to only collect essential information to better understand your use of our website.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.