Accueil » Vue d’ensemble
La solution SaaS pour la sobriété et la performance de vos applications mobiles et web.

Préparez et lancez des mesures de Parcours utilisateur sur les terminaux de notre banc de test. Choisissez le terminal et le réseau selon vos objectifs.
Analysez les résultats à l’échelle du parcours (impact CO2, écoscore) et de chaque étape du parcours
Identifier les points de surconsommation, les défauts de performance, et améliorez la sobriété du Parcours !

Simple en apparence, l’écoscore Greenspector est basé sur une analyse complète de toutes les étapes du parcours utilisateur, sur 3 axes différents, en tenant compte du caractère critique ou non des étapes mesurées. L’écoscore Greenspector est vraiment représentatif du niveau de sobriété de votre parcours.
Avec Greenspector Studio, obtenez une évaluation rigoureuse et précise de l‘impact carbone et d’autres indicateurs environnementaux. –> en savoir plus sur les impacts (méthodologie, indicateurs…)
Décrire un parcours utilisateur est simple et rapide grâce au GDSL, notre langage exclusif. Il est constitué de mots clés simples (cliquer, attendre…), mais puissant pour reproduire fidèlement les parcours utilisateurs les plus complexes.
Utilisez un seul langage pour vos parcours Android, iOS et Web.


Sélectionnez le modèle de terminal qui correspond à vos objectifs de test.
Un terminal « moyen » pour les mesures courantes, ou un modèle plus ancien pour vérifier si le parcours peut être réalisé par des utilisateurs moins favorisés ? Et pourquoi pas en connexion 3G, pour tester la dépendance du parcours à la qualité du réseau ?
Pour tester vos applications métiers, demandez-nous d’ajouter sur le banc tests un terminal issu de votre flotte mobile (en option).

Sélectionnez le modèle de terminal qui correspond à vos objectifs de test.
Consultez le tableau de bord pour identifier rapidement les points du parcours qui posent problème : surconsommation d’énergie, souci de performance, problème de requêtes ou service tiers… L’interface propose plusieurs niveaux de lecture, du plus simple au plus détaillé, pour aider toute votre équipe à comprendre.
Faites des regroupements par domaine fonctionnel pour faciliter la lecture.
Vous savez quelles sont les étapes à améliorer pour gagner en sobriété, améliorer la performance et réduire les impacts. Vous pouvez prioriser vos efforts efficacement.

Lancez une mesure avant chaque version pour éviter les anomalies et piloter en surveillant l’évolution des indicateurs.
Utilisez les API pour déclencher les tests depuis votre CI/CD (GitLab CI, Azure CI, Jenkins…). Utilisez d’autres API pour exporter les résultats vers vos propres tableaux de bord.

Toutes vos équipes n’ont pas la même maturité ni la même disponibilité. Comment faire pour avoir une première idée de l’impact de leur Produit, sans perturber leur travail ?
Grâce à notre test WebMark intégré, obtenez en 1 clic un score et un impact carbone de n’importe quelle page. Idem pour les applis Android avec AppMark.
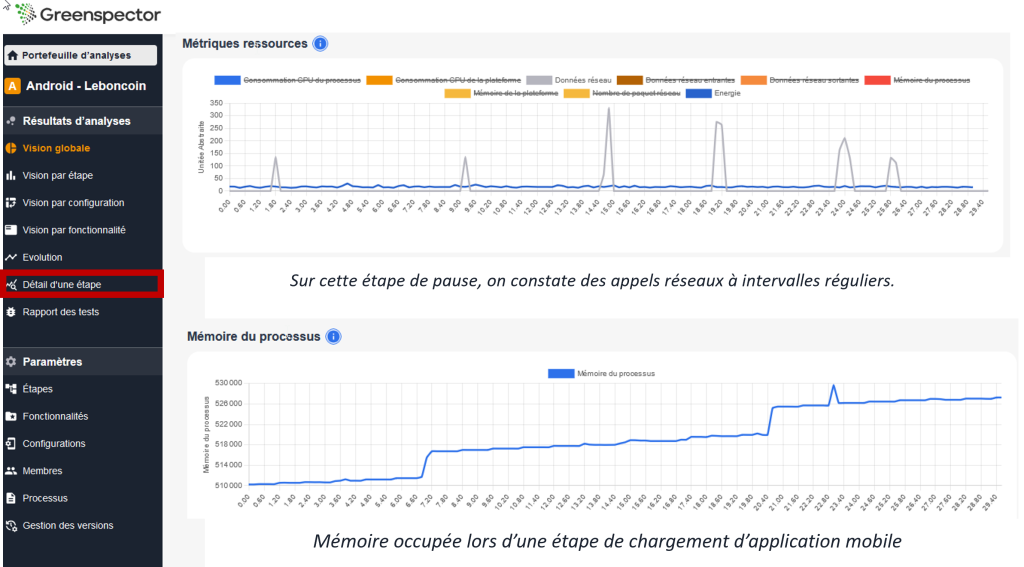
Pour aller plus loin, observez des métriques supplémentaires permettant d’analyser finement le comportement du logiciel (énergie, données entrantes/sortantes, CPU, mémoire, métriques système Android… Certaines métriques sont disponibles uniquement sur terminaux Android).
La mesure directe et ultra-précise de la consommation de batterie tout au long du parcours utilisateurs apporte un nouveau regard sur le comportement de votre application.
Travailler sur la sobriété permet clairement d’obtenir une application plus performante.

Julien AZRIA
Digital Front Chapter Leader, Crédit Agricole Technologie & Services
Certaines fonctionnalités décrites peuvent ne pas être disponibles selon le niveau d’abonnement souscrit. Merci de vous référer à notre page Tarifs.
Reconnu dès 2020 par la Fondation Solar Impulse parmi les 1000+ « solutions efficientes pour protéger l’environnement »
Nos innovations sont le fruit de notre R&D. Notre contribution aux travaux scientifiques a été exposée dans de nombreux articles et conférences internationales
Notre modèle d’impacts est compatible avec les standards du domaine : ACV (ISO 14040), SCI de Green Software Foundation, RCP ADEME…



