Chez GREENSPECTOR, nos équipes R&D travaillent depuis plusieurs années sur la mesure d’énergie des smartphones. Plusieurs années de recherche et innovation qui nous permettent aujourd’hui de proposer un produit unique permettant de mesurer simplement les données d’énergie des smartphones. Il existe néanmoins des outils qui permettent de compléter l’analyse du comportement de la batterie et du téléphone. Battery Historian en fait partie.
Battery Historian est un outil développé par Google, lancé en 2016, qui permet d’analyser le comportement d’un téléphone et plus exactement d’examiner les informations et évènements liés à la batterie. Il s’agit, nous le verrons, d’un outil d’analyse pour expert. Plusieurs métriques et insights sont disponibles : cellules radio, communication… tout cela corrélé au niveau de batterie.
Tutoriel d’usage de Battery Historian
1) Dans un premier temps, installez Docker. Docker est un logiciel libre qui automatise le déploiement d’applications dans des conteneurs logiciels. Pour ma part, je suis sur Ubuntu donc j’utilise les scripts d’installation rapide :
curl -fsSL get.docker.com -o get-docker.sh
sudo sh get-docker.sh
2) Depuis votre interface de ligne de commande, lancez l’image Docker :
docker run -d -p 9999:9999 bhaavan/battery-historian
3) Vous pouvez désormais accéder à Battery Historian depuis l’adresse localhost:9999
Vous devez maintenant récupérer les informations détaillées du système de votre téléphone. Pour cela, vous devez avoir préalablement installé le SDK Android et être passé en mode développeur sur votre téléphone.
4)Branchez votre téléphone en USB à votre PC.
5) Depuis votre interface de ligne de commande, récupérez le fichier d’information système du téléphone avec la commande suivante :
adb bugreport bugreport.zip
6) Vous pouvez désormais uploader le fichierbugreport.txt dans Battery Historian
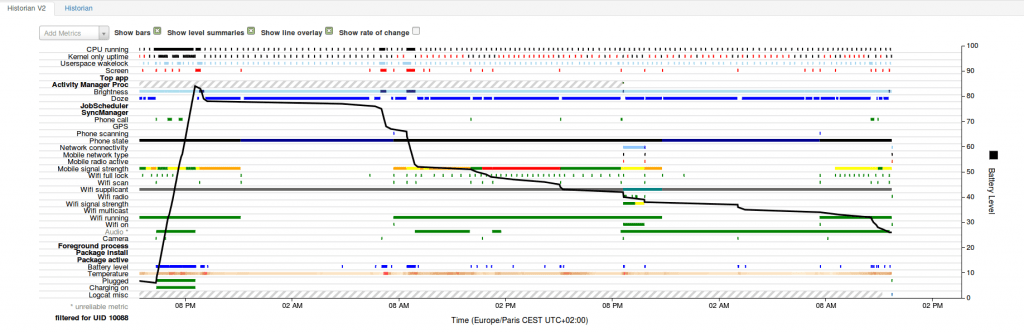
Vous obtiendrez alors votre analyse :
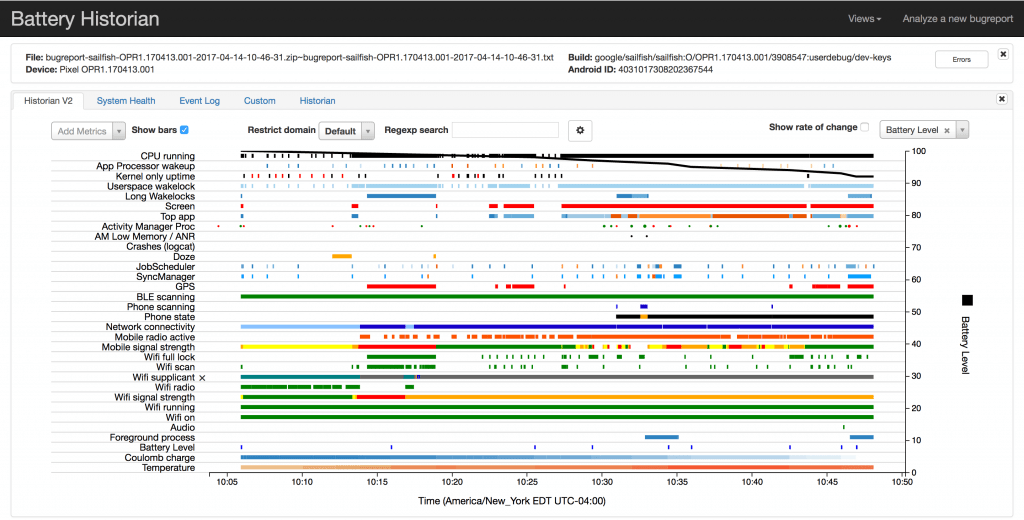
Vous pouvez observer le niveau de batterie sur l’axe de droite (de 0 à 100%), ce niveau est représenté par la courbe noire. Sur l’axe de gauche et les autres lignes, vous trouverez toutes les autres informations sur les métriques et insights remontés par le système.
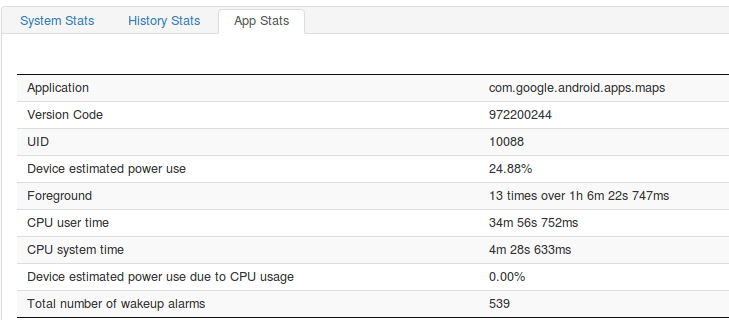
En dessous de ce graph, vous retrouverez des statistiques de toutes les informations sur des applications spécifiques ou informations système de votre téléphone. Vous permettant une vision d’ensemble de ce qui se passe avec votre device. Vous pourrez par exemple analyser l’impact d’une application particulière sur la batterie au cours de l’usage :
Notre avis sur Battery historian
Battery Historian est un outil puissant qui vous permet d’analyser le comportement de la batterie et surtout comprendre ce qui se passe dans le système. Mais c’est aussi un outil complexe. Il y a énormément d’informations et il devient vite casse-tête de trouver les causes de la décharge. De plus, l’outil étant basé sur le niveau de batterie, il est nécessaire de laisser tourner un certain temps l’application que vous souhaitez analyser. Il s’agit donc d’un outil utile pour une analyse détaillée du système mais à mettre dans des mains expertes.
Expert Sobriété Numérique Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», … Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …) Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels
Nous portons de l’importance à l’efficience de vos applications, c’est pourquoi nous vous présentons cet *Ultimate Metric Guide: le glossaire pour mieux gérer la mémoire de vos applications sur appareils Android.**
Syllabus de la mémoire
Pages: Blocs utilisés pour récupérer des données du disque à la mémoire. C’est la partie principale de la gestion de mémoire virtuelle. En général, la taille de la page est de 4kb.
Mémoire privée / partagée(Private / Shared memory): La mémoire privée est composée de pages qui sont utilisées par le processus seulement. La mémoire partagée, quant à elle, est faite de pages utilisées par d’autres processus. Il est possible qu’une page passe de Privée à Partagée si un processus référence la page en question.
Clean / Dirty memory: Les pages “dirty” sont celles sorties du disque. Par conséquence, les pages “clean” sont celles qui ont été lues.
VSS (Virtual Set Size): C’est le nombre total de pages accessibles par un processus. Cela inclut à la fois les pages privées et partagées, mais aussi d’autres espaces de mémoire comme malloc. Cela est peu, voir pas, utilisé.
RSS (Resident Set Size): Total des bibliothèques partagées. Pas d’information sur le nombre de processus utilisant la page. Par conséquent, cela n’est pas une information très utile (La PSS est plus importants).
Pss (proportional set size): Le nombre de pages un processus a en mémoire, dans lequel les pages privées et pages partagées sont additionnées et divisées par le nombre de processus les partageant. Si un processus a 2 pages privées et 6 autres pages privées utilisées par 2 autres processus, le « pss » en nombre de pages est de 2+6/3=4.
Uss (Unique set size): Le nombre de pages uniques associées à un processus, et donc de pages privées ! Généralement VSS > RSS > PSS > USS
Java / native memory: La mémoire Java est la mémoire gérée par le système Android (Dalvik ou ART). Principalement pour vos objets Kotlin ou Java ! La mémoire native est quant à elle plutôt pour les objets générés. Même sans application C/C++, le framework Android utilise parfois la méthode native.
ZRam: Android n’a pas de partition swap, Zram est la RAM mais une compression est utilisée pour stocker les données inutiles. Sur meminfo, « swapped dirty » paraît être équivalent.
Stack / heap: Heap est l’espace mémoire objet, et les variables locales sont allouées à Stack. Par conséquent, les objets sont créés sur Heap. Chaque thread a un espace Stack. Allocated Heap Size : Android est un système multitâche ; afin de garder de l’espace mémoire pour d’autres processus, il affecte une taille de la mémoire dans la mémoire globale. Cette taille varie selon le smartphone. Si votre application requiert davantage de mémoire, vous obtiendrez la célèbre erreur « mémoire insuffisante » (« out of memory »).
MMAP: Dénommé “map file to memory” par le système. Sur Android, il y des mmap pour chaque type de dossier (Dex, APK, ART. Peut être nommé “Code” dans certains outils.
Graphics Buffer: Mémoire utilisée pour stocker les objets graphiques.
User/Kernal memory: Le processus tourne dans l’espace utilisateur. L’espace Kernel est dédié aux calls du système Android.
Organisation mémoire
La mémoire Android est organisée par un système d’adresses virtuelles. Le mapping est le suivant: (adresses ascendantes)
User Space
Data space (texte, données, instructions…)
Heap
libs (bibliothèques partagées, .jar…)
Stack
Kernel Space
La mémoire utilisée par votre application se trouve dans le user space (principalement en heap et stack).
Outils
Paramètre système Android: Les données dans l’interface utilisateur Android fournissent deux informations : la consommation maximale et la moyenne d’information (3 heures). La moyenne est relativement compliquée à analyser et la consommation maximale est une première indication intéressante pour l’utilisateur.
Top: Parce que l’on utilise déjà les RSS et VSS, les informations Top ne sont pas particulièrement significatives.
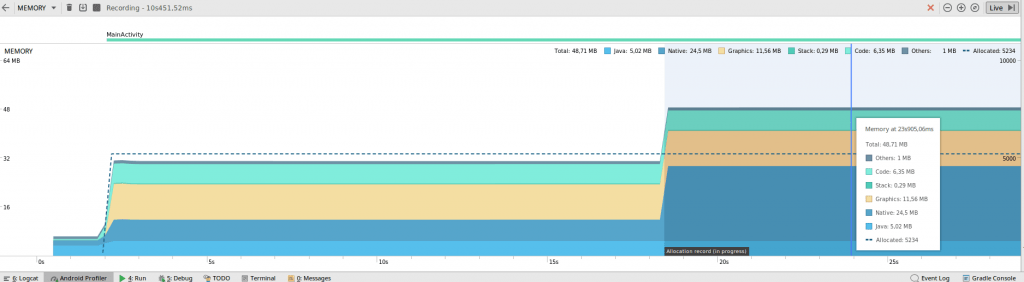
Memory Profiler in Android Studio (>3.0): Uniquement la mémoire privée est mesurée et se divise en différents domaines:
Native / Java
Code
Graphics Buffer
Android Monitor in Android Studio (<3.0): Uniquement la mémoire privée est mesurée . Moins de domaines sont mesurés que dans Android Memory > 3.
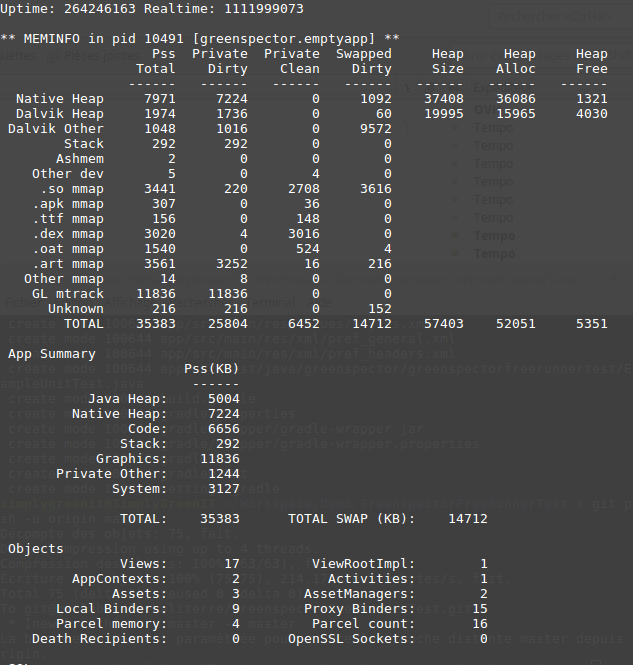
Dumpsys: Dumpsys mesure la mémoire PSS (à la fois privée et partagée) mais aussi le SWAP dirty.
Android MemInfo API: La mémoire PSS ets utilisée (privée et partagée)
/proc/meminfo: C’est la mémoire globale de la plateforme, pas d’information sur votre processus.
Quelles métriques doit-on utiliser ?
Mémoire privée/USS: Cette mémoire est dédiée à votre processus. Il est donc intéressant d’analyser précisément l’objet dédié à votre application. Par exemple, si vous tuez votre processus, la mémoire dédiée doit être de zéro, cela vous permet donc de détecter une potentielle fuite de mémoire. Néanmoins, votre application a utilisé des bibliothèques et des codes partagés, par conséquent vous ne verrez pas de mémoire qui pourra être partagée avec d’autre processus.
PSS/Mémoire privée et partagée: C’est plus compliqué d’analyser cette mémoire car elle intègre la mémoire de différents processus (avec un facteur de correction). Cependant, pendant vos mesures, si vous fermez les autres apps en cours d’exécution en arrière-plan, cet impact sera minimisé.
VSS/RSS: Trop de pages de mémoire sont prises en compte dans cette métrique, elle n’est donc pas intéressante à analyser.
Comment tester la mémoire ?
Statique: Vous avez seulement à exécuter votre application et lancer les outils de mémoire. Cela permet d’avoir une vue globale de la consommation en mémoire de votre application. Vous pouvez utiliser cette technique pour réduire la mémoire totale utilisée : code, java heap,…
En longueur: Vous laissez les outils s’exécuter et observez les évolutions en matière de mémoire. Par ce moyen, vous pouvez identifier une fuite de mémoire potentielle ; la mémoire augmente régulièrement : s’il y a un « garbage collector » réduisant fréquemment la mémoire à sa valeur initiale, il n’y a pas de problème, si non, il y a une fuite.
Passer d’une activité à une autre: Vous pouvez aller entre les pages et voir si la mémoire est libérée à chaque fois. Cela est possible avec des tests Monkey.
Ecran rotateur: Si vous tourner votre écran, l’activité de votre application créera potentiellement une fuite de mémoire.
Mettre l’application en arrière-plan: Si votre application est en arrière-plan, une partie de la mémoire sera libérée (par exemple la graphique). Vous pouvez aussi libérer davantage de mémoire (objet, bibliothèque…).
Comment réduire la mémoire?
Optimiser l’image: Les images sont une cause de consommation de mémoire assez importante. Vous pouvez utiliser la Bibliothèque Glide pour vous aider à les gérer ou encore à en optimiser la gestion avec Android API.
Libérer de la mémoire quand Android requiert advantage de mémoire : Comme le système est pauvre en mémoire, une notification est envoyée à toutes les applications pour libérer de la mémoire. Dans ce cas-là, passez outre onTrimMemory() pour libérer de la mémoire.
Utiliser une structure spécifique: Les collections génériques comme hashmap ne sont pas dédiées à Android, certaines structures sont plus adaptées, comme SparseArray.
Réduire la taille de votre APK: La taille de votre APK (particulièrement les ressources et bibliothèques) peuvent augmenter la consommation de mémoire.
Réduire le nombre de threads: Android fournit des services pour faire des petites tâches et éviter la surconsommation de mémoire, comme AsyncTask.
Préférer les classes internes statiques : Les classes internes non-statiques créent des références étrangères à cette activité. C’est une cause de fuite de mémoire. Vous devriez choisir celles statiques.
FAQ
Comment connaître la taille limite du heap?: La taille limite du heap d’Android dépend de l’appareil (de 15Mb à quelques centaines). Afin de connaître la taille limite, vous pouvez utiliser l’API de getMemoryClass() du service ActivityManager.
Les informations de mémoire ne sont pas identiques selon les différents outils. Pourquoi ?: Les outils peuvent utiliser des APIs de différents systèmes ou simplement ne pas prendre en compte les mêmes données (par exemple ne pas prendre le MMAP). Dans la plupart des cas : Android monitor < Android Profiler in Android Studio < dumpsys < System Meminfo api < top info and VSS > RSS > PSS > USS
Android libérera-t-il la mémoire de processus pendant le mode arrière-plan ?: Quand l’utilisateur change l’app, le système « cache » l’app dans le cache utilisé le moins récemment (LRU – least recently used cache). Le système fonctionnant avec peu de mémoire, il va tuez (kill) les applications consommatrices. Si votre app consomme peu de mémoire, elle a ses chances de ne pas être tuée (ou du moins, seulement après les apps consommant davantage).
Est-il possible d’augmenter la taille limite du heap ?: Oui, avec l’option android:largeHeap=true dans le manifeste. Cela n’est cependant pas recommandé.
Qu’est-ce que “OutOfMemoryError” ?: Votre application a besoin de plus d’espace et vous avez atteint la taille limite du heap.
Expert Sobriété Numérique Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», … Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …) Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels
Lors du développement d’un objet connecté, l’autonomie est un de critères les plus importants à tester. Ne pas mesurer la consommation énergétique do votre plateforme peut potentiellement mener à certains problèmes, comme:
Une insatisfaction des utilisateurs
Une baisse de la durée de vie d’une batterie
Une augmentation du coût de maintenance de la plateforme
Mais comment pouvons-nous donc mesurer l’énergie ?
Sur ce blog, nous avons déjà expliqué plusieurs fois comment mesurer l’énergie avec uniquement un logiciel, plus particulièrement sur Android. Mais la mesure sur plateforme IoT n’est pas si simple : pas de sonde énergétique embarquée, pas d’API… Il faudra donc faire des mesures du matériel.
Explications électriques
Pour mesurer la consommation énergétique il faut utiliser un shunt. C’est un resistor qui est à placer dans votre circuit électrique : quand le courant passe à travers le resistor, une tension différentielle se crée. Et l’énergie peut se calculer avec la loi d’Ohm : Energie = Tension x Courant.
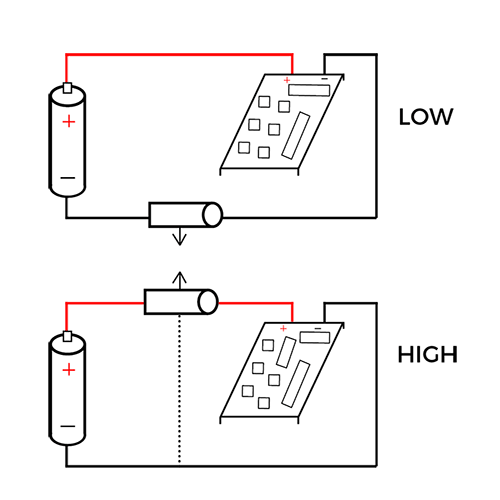
On intègre ce shunt de deux manières : haute tension et basse tension. Le fait de choisir haute ou basse dépend de la position du shunt, selon la batterie et l’énergie à l’intérieur. La position « Haute » est localisée entre le point positif de la batterie et votre charge (plateforme), et la « Basse » se positionne entre la masse de batterie et la masse de plateforme.
Le côté Basse tension présente quelques désavantages, plus particulièrement liés à la commutation de la charge qui crée des problèmes de boucle de masse. C’est généralement le cas pour l’IoT, avec les capteurs, régulateurs, etc… Choisissons plutôt donc de mesurer le côté Haute tension !
Mesure rapide d’une plateforme IoT
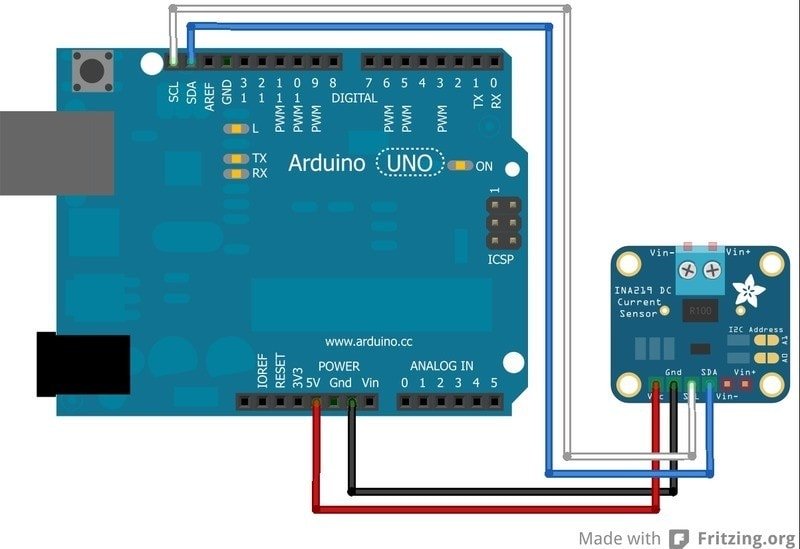
Arduino fournit un tutoriel axé sur la mesure d’énergie avec une breakout board INA219 et une précision à 1%.
La câblage est plûtot facile à réaliser en utilisant une breadboard et en suivant le tutoriel Adafruit.
Pour tester votre installation, vous pouvez essayer avec un exemple. Vous obtiendrez alors quatre informations :
Tension du Bus : la tension totale perçue par le circuit pendant un test. (Tension d’alimentation – tension shunt)
Tension du Shunt : et bien… la tension du shunt !
Courant : le courant dérivé via la loi d’Ohm et la mesure de la tension
Tension sur charge : la tension globale
Mesure d’un objet IoT
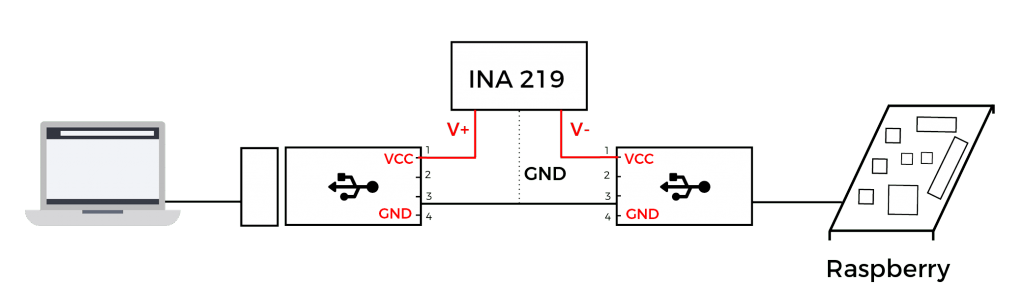
Nous pouvons maintenant intégrer la plateforme IoT et pour cela nous avons choisi un Raspberry, ce qui est plutôt cool à mesurer avec un Arduino !
La première difficulté rencontrée est l’insertion du shunt entre le point d’énergie positif de la batterie et le Vin du Raspberry. Dans un premier temps, vous pouvez l’intégrer directement sur la board Raspberry, en coupant le circuit. Mais nous avons choisi une option moins intrusive, consistant à l’intégrer dans le câble d’alimentation. Raspberry étant alimenté par USB, nous devons donc placer le shunt entre le V+ de l’ordinateur et le V+ du Raspberry :
En situation réelle, cela donne cela :
Vous devez maintenant lancer le code exemple pour obtenir le courant et la tension de la plateforme. Pour un Raspberry sans aucune configuration particulière (sans OS, sans carte) j’ai obtenu une puissance moyenne de 230 mW.
Ensuite, vous n’avez plus qu’à initier les mesures de vos différents projets ! Par exemple, vous verrez ici comment j’ai mesuré une station météo Arduino.
Expert Sobriété Numérique Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», … Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …) Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels
Comme son nom l’indique, UI Automator est un framework fourni par Android permettant d’exécuter des tests fonctionnels d’interface utilisateur (UI pour User Interface en anglais) de façon automatisée.
Ce framework permet d’interagir avec les éléments visibles sur l’écran du smartphone : cliquer sur un bouton, remplir un champ texte, scroller, etc. Grâce à UI Automator, vous pouvez par exemple lancer une application, remplir un formulaire de login, naviguer dans les menus…
Écrivons ensemble un premier scénario de test avec UI Automator ! Notre objectif sera modeste : lancer une vidéo depuis l’application YouTube pour Android.
UI Automator, Espresso, Appium…
Dans le framework Android, vous trouverez aussi Espresso : quelle est la différence ?
UI Automator est plutôt orienté tests « boîte noire » : vous pouvez tester n’importe quelle application (même si vous n’avez pas le code) ou même accéder à des paramètres systèmes d’Android (par exemple le panneau de configuration).
Espresso, lui est plutôt orienté tests « boîte blanche » : vous devez avoir le code de l’application à tester, vous pouvez effectuer des assertions plus fines (par exemple sur la création d’activité dans l’application).
Il existe également d’autres outils, comme Appium, mais qui ne sont pas intégrés dans le framework Android. Ils ont l’avantage d’offrir des fonctionnalités en plus et des couches d’abstractions supplémentaires. C’est cependant au prix d’une certaines complexité de mise en place.
Vous l’aurez compris, UI Automator est pour nous le plus adapté et le plus simple pour commencer rapidement !
Première étape : mettre en place l’environnement de travail
Les tests UI Automator font partie de la famille des test instrumentés : ils doivent être exécutés sur un smartphone ou sur un émulateur Android. Pendant le test, deux APK s’exécutent au sein du même processus : un premier APK pour l’application à tester et un deuxième APK pour le test.
Vous avez donc besoin d’une application (et d’un scénario !) à tester.
Le code source d’une application Android est usuellement organisé de la façon suivante :
module
|---src
|---androidTest
|---main
|---test
Premier cas : vous êtes le développeur de l’application à tester. La solution la plus simple consiste alors à développer les tests dans le même module que l’application. Le dossier main contiendra alors le code source de votre application et le dossier androidTest vos tests UI Automator.
Deuxième cas : vous n’avez pas le code source de l’application à tester. Il vous suffit alors de créer un nouveau module : le dossier main sera vide et, comme précédemment, le dossier androidTest contiendra vos test UI Automator.
Dans le fichier build.gradle du module, ajoutez les configurations suivantes (UI Automator fonctionne avec AndroidJUnitRunner) :
Après vous être assuré que le projet compile correctement, il est temps d’ajouter une nouvelle classe dans module/src/androidTest :
@RunWith(AndroidJUnit4.class)
public class YouTubeTest {
@Test
public void watchVideo() throws Exception {
// TODO
}
}
Tout est maintenant prêt pour l’implémentation du scénario de test !
Deuxième étape : écrire les tests
Quelques petites précisions avant de se lancer…
UI Automator permet d’interagir avec les éléments visibles sur l’écran. Chaque élément possède un certain nombre de propriétés, parmi lesquelles : content-description, class, resource-id, text.
UI Automator permet de rechercher un élément vérifiant une propriété donnée. Par exemple, pour accéder au bouton Valider affiché sur votre écran, vous pouvez rechercher l’élément dont la propriété text vaut Valider. Mais vous pouvez aussi être plus spécifique, par exemple : l’élément dont la class est android.widget.EditText et la content-description est text_name.
La (ou les) propriété(s) utilisée(s) pour rechercher un élément a son importance. Par exemple, méfiez-vous des libellés, notamment si votre application est disponible en plusieurs langues !
Afin de connaître les propriétés des éléments visibles sur l’écran, il est très pratique d’utiliser l’outil Android uiautomatorviewer (que vous trouverez dans le répertoire tools de votre SDK Android). Une fois lancé, cet outil permet de faire des captures d’écran d’un smartphone Android. À chaque capture d’écran est associée un arbre représentant la hiérarchie des éléments visibles, avec leurs propriétés respectives.
Revenons à notre scénario de test, pour lequel nous nous proposons d’effectuer les actions suivantes :
lancer l’application YouTube ;
cliquer sur la loupe pour effectuer une recherche ;
indiquer le texte « greenspector » dans le champ de recherche ;
lancer la vidéo « Power Test Cloud – Greenspector (FR) » ;
regarder les 20 premières secondes de la vidéo.
Avant de démarrer toute interaction avec les éléments sur l’écran, il faut instancier un objet UiDevice qui représentera l’état actuel de l’écran du smartphone.
Commençons par lancer l’application YouTube, comme expliqué dans la documentation Android. L’objet de cet article étant de dérouler quelques fonctionnalités les plus simples d’UI Automator, cette étape n’est pas détaillée.
L’étape suivante consiste à cliquer sur la loupe pour effectuer une recherche. Après avoir repéré le resource-id de la loupe grâce à uiautomatorviewer, nous utilisons la méthode waitForExists permettant d’attendre que l’élément apparaisse avant de cliquer sur l’objet.
Précédemment, nous n’avons utilisé qu’un seul critère pour rechercher les éléments sur l’écran. Mais il est possible d’en combiner plusieurs (si certaines propriétés ont la même valeur pour plusieurs éléments), par exemple :
UiObject video = mDevice.findObject(new UiSelector()
.resourceId("com.google.android.youtube:id/title")
.text("Power Test Cloud - Greenspector (FR)"));
Enfin, attendons quelques secondes en regardant le début de la vidéo.
synchronized (mDevice) {
mDevice.wait(20000);
}
Troisième étape : exécuter les tests
Afin d’exécuter les tests, il est nécessaire d’être connecté via ADB à un smartphone (soit un smartphone physique « réel », soit un émulateur Android). Le lancement peut s’effectuer directement depuis Android Studio, ou bien en ligne de commande avec ADB.
Premier cas : depuis Android Studio.
Se rendre dans le menu Run, puis Edit configurations. Cliquer sur le signe + pour ajouter une configuration, sélectionner le modèle Android Instrumented Tests. Adapter la configuration avec le nom du module à tester, le type de test, le smartphone (réel ou émulateur).
Deuxième cas : en ligne de commande avec ADB.
Tout d’abord, compiler l’application ainsi que les tests, par exemple en utilisant les tâches assemble et assembleAndroidTest du wrapper Gradle :
$ ./gradlew clean assemble assembleAndroidTest
Puis installer sur le smartphone les fichiers .apk générés :
Expert Sobriété Numérique Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», … Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …) Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels
Le protocole HTTP 1.1 a été mis en place il y a 20 ans. Avec ce protocole basé sur le texte, l’inconvénient principal en termes de performance et efficience est la latence. Chaque fois qu’un élément est demandé par la page web (comme des images, une fonction JavaScript…), une connexion TCP se lance avec le serveur, avec parfois des latences, en fonction du réseau (qui se joue en fonction de nombreux paramètres, notamment la distance entre l’utilisateur et le serveur web).
Cet effet est renforcé par le fait que les navigateurs plafonnent le nombre de connexions simultanées, habituellement à un maximum de cinq. Le protocoleHTTP2 – sorti en milieu d’année 2015 – présente des améliorations, notamment sur ce souci de latence. Comment cela se présente-t-il ? En diffusant et multiplexant des trames binaires plutôt que de gérer des éléments textes. Maintenant, il n’y a plus qu’une seule connexion TCP et les téléchargements se font en parallèle. Nous obtenons donc un résultat sans plus aucun overhead lié aux négociations TLS.
Il est maintenant clair que HTTP2 améliore la performance de sites et applications web. Mais qu’en est-il de l’efficience énergétique ? En effet, meilleure performance n’est pas forcément synonyme de meilleure efficacité et c’est ce que je voulais vérifier. Allez, regardons ça !
Mettre en place un serveur HTTP2 avec @Golang est relativement simple. Un démonstrateur public permet de tester la mise en œuvre et la performance. Pour faire cela, une image composée de 180 carreaux est en place et peut être vue de plusieurs manières différentes, illustrant les différents paramètres de latence :
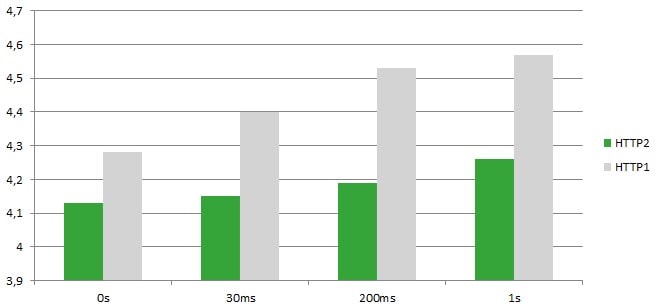
J’ai mesuré la consommation énergétique nécessaire pour afficher cette page web sur un smartphone Nexus 6, et voici les résultats que j’ai eus :
Nous pouvons y voir que, pour les mêmes valeurs de latence (0s, 30ms, 200ms, 1s), le HTTP2 est plus efficienten termes d’énergie, avec environ 8% de consommation énergétique en moins.
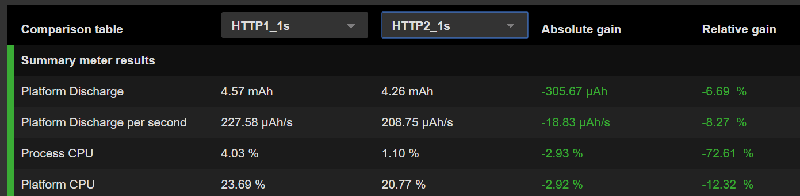
Cette capture écran de GREENSPECTOR montre les différences entre HTTP1 et HTTP2 dans le cas de scenarios de latence d’une seconde. Vous noterez aussi le gain de 8.3% de déchargement de la plateforme à la seconde (Platform Discharge per second).
De plus, quand la latence augmente, HTTP2 permet l’absorption de davantage de perte de performance :
Pour HTTP1 : 4,13 mAh à 4,26 mAh (+3%) quand la latence passe de 0s à 1s
Pour HTTP2 : 4,28 mAh à 4,57 mAh (+6%) quand la latence passe de 0s à 1s
CONCLUSION
En conclusion, HTTP2peut en effet améliorerl’efficacité énergétique d’un site web du côté du client. En tant que propriétaire de site internet, c’est une bonne chose que de faire ça, cela préserve la batterie de vos utilisateurs. Mais il y a encore mieux ! Vu que HTTP2 groupe les requêtes, le serveur est chargé pendant une période de temps réduite : et donc, les ressources du serveur sont libérés plus tôt et donc disponibles plus rapidement pour les autres utilisateurs.
Terminons avec une mise en garde pour ce cas d’usage : cette petite étude n’est qu’un rapide examen et non pas un cas réel, doté de différents éléments ou encore CDN. Le test est donc à poursuivre plus en profondeur. Cela dit, HTTP2 promet de belles choses en termes d’efficience énergétique.
Expert Sobriété Numérique Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», … Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …) Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels
Vous le savez, une application de qualité ne doit pas consommer trop de ressources sur le smartphone de l’utilisateur. C’est nécessaire à son adoption et à son utilisation.
Vous avez donc décidé de vous retrousser les manches et de contrôler cette consommation de ressources (CPU, mémoire, data…), l’énergie, la taille de l’application. Vous maîtrisez les bonnes pratiques et le langage de développement, mais l’enfer est pavé de bonnes intentions ! Quelle est la boîte à outils pour bien commencer ? Passons en revue les meilleurs outils pour le développeur Android.
Android Studio
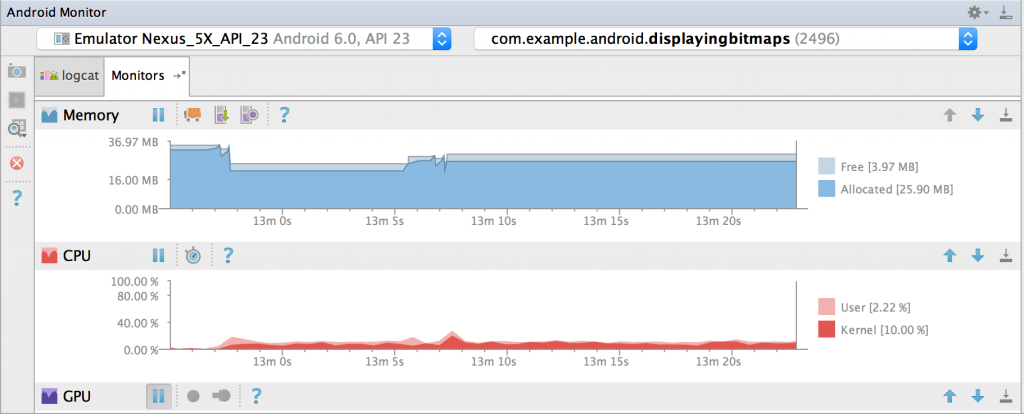
Android Studio intègre maintenant de nombreux outils pour suivre la consommation de ressources de votre application. L’avantage est l’intégration de l’outil dans votre environnement de développement. On ne peut pas être plus proche de votre travail au jour le jour. Cependant, il faudra aller chercher dans les sous-menus et penser à suivre les métriques.
La dernière version intègre maintenant la possibilité de profiler le réseau et même les librairies comme OKHTTP :
Les outils du SDK : Traceview
Traceview permet de visualiser les appels de méthodes, le temps passé dans chacune… L’outil est très puissant mais vous passerez sûrement du temps à analyser les données. Il est possible que vous vous perdiez dans la hiérarchie des appels. Cependant cet outil est incontournable pour analyser des problèmes de performance (entre autres).
Les outils du SDK : Systrace
Systrace est un autre outil de profiling très puissant. Il permet de visualiser des informations sur le matériel (le travail du CPU avec la répartition sur tous les CPUs) mais aussi des packages d’informations Android (RenderThread, Event…). Comme tout bon outil de profiling, il présente beaucoup d’informations. L’inconvénient est qu’il faut prendre le temps de comprendre toutes ces informations, ce qui peut facilement se révéler assez chronophage.
Les outils du SDK : Dumpsys
Dumpsys est un module en ligne de commande du système Android. De nombreuses informations peuvent être obtenues : informations sur les vues, sur la base … L’inconvénient de cette solution est la complexité des métriques, donc la nécessité de passer du temps pour analyser et relancer les mesures. Par exemple, taper la ligne suivante dans la ligne de commande pour avoir les informations sur les traitements graphiques : adb shell dumpsys gfxinfo
Si vous avez activé le mode développeur, vous aurez des outils qui vous permettent de mesurer certaines métriques comme la performance d’affichage, le CPU… Ce mode est très intéressant mais la nécessité de devoir effectuer des actions manuellement sur le téléphone en limite la puissance.
A noter, la possibilité de mettre en surbrillance des zones qui sont dessinées. Cela permet par exemple d’identifier des redraws trop fréquents.
Les outils Android non intégrés dans le SDK : Battery Historian
Battery historian est un outil qui va visualiser les informations issues de dumpsys batterystats. La décharge batterie est donc visible en parallèle des traitements système et de l’usage des composants. Vous pourrez ainsi détecter des problèmes de fuite d’énergie. La limite est qu’il est nécessaire de faire tourner l’application plusieurs minutes ce qui augmente la complexité d’analyse :on est proche d’un outil de profiling avec la complexité associée.
Les outils d’automatisation : GREENSPECTOR
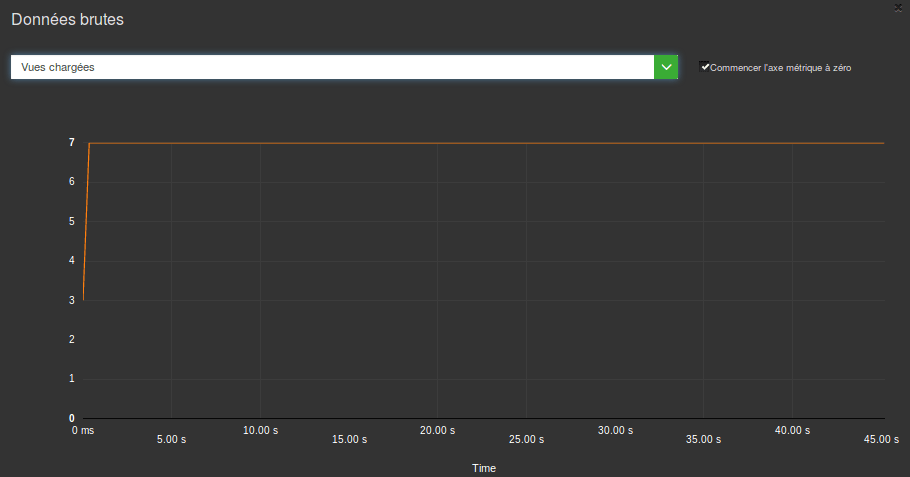
Évidemment nous ne pouvons pas passer en revue ces outils sans parler de GREENSPECTOR. Les outils dont nous venons de parler sont puissants, mais leur puissance se paie par leur complexité importante, qui demande une expertise certaine pour bien en retirer les informations recherchées. Or très souvent, ces outils ne sont invoqués qu’en cas de crise, quasiment jamais de façon régulière. Pourtant il semble intéressant de réaliser des mesures de consommations de ressources tout au long du développement et pour tous les développeurs. C’est pour cela que GREENSPECTOR est utilisable en intégration continue. Au-delà des métriques usuelles, nous avons intégré une partie des outils experts (comme Dumpsys) directement dans GREENSPECTOR. L’objectif est d’allier la simplicité de l’interface, pour une surveillance en continu, et l’apport d’informations plus « pointues » en cas de besoin.
Voici par exemple une courbe sur les vues Android lors du lancement de l’application suite à un test en intégration continue :
Cette manière de mesurer nous permet de détecter facilement des problèmes de consommation. L’analyse plus poussée pourra ensuite être faite avec les autres outils mentionnés si elle s’avère nécessaire.
Expert Sobriété Numérique Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», … Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …) Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels
Les algorithmes SEO de Google se basent sur 3 domaines :
le crawling qui va permettre à Google d’évaluer vos pages en termes de temps de réponse, de qualité technique ;
l’indexation qui va analyser le contenu (fraîcheur, richesse, qualité…) ;
le ranking pour analyser la popularité de votre site.
Le crawling est une des parties les plus importantes, car c’est la manière dont Google va « afficher » vos pages. Les robots de Google (ou GoogleBots) vont analyser chaque url et les indexer. Le processus est itératif : les bots reviendront régulièrement réanalyser ces pages pour identifier les éventuels changements.
La notion de Crawl budget
L’effort que les bots de Google vont fournir pour analyser votre site va influencer le nombre de pages qui seront référencées, la fréquence des vérifications ultérieures, ainsi que la notation globale de votre site. L’algorithme de Google est en effet dicté par un « effort maximum à fournir » qu’on appelle le « crawl budget« . Google le définit comme ceci:
Crawl rate limit Googlebot is designed to be a good citizen of the web. Crawling is its main priority, while making sure it doesn’t degrade the experience of users visiting the site. We call this the « crawl rate limit » which limits the maximum fetching rate for a given site. Simply put, this represents the number of simultaneous parallel connections Googlebot may use to crawl the site, as well as the time it has to wait between the fetches. The crawl rate can go up and down based on a couple of factors: Crawl health: if the site responds really quickly for a while, the limit goes up, meaning more connections can be used to crawl. If the site slows down or responds with server errors, the limit goes down and Googlebot crawls less. …
Autrement dit, Google ne veut pas passer trop de temps sur votre site, pour pouvoir consacrer du temps aux autres sites. Donc s’il détecte des lenteurs, l’analyse sera moins poussée. Toutes vos pages ne seront pas indexées, Google ne reviendra pas si souvent, résultat : vous allez perdre en référencement.
Une autre explication à cette logique de budget, est que le crawling coûte de la ressource serveur à Google et que cette ressource a un coût. Google est une entreprise non philanthropique. Il est compréhensible qu’elle veuille limiter ses coûts de fonctionnement tel que celui du crawling. Au passage, cela permet aussi de limiter l’impact environnemental de l’opération, ce qui est un point important pour Google.
Sachez où vous en êtes
Il est donc nécessaire de surveiller le budget crawling et la manière dont Google analyse votre site. Cela peut se faire de différentes manières.
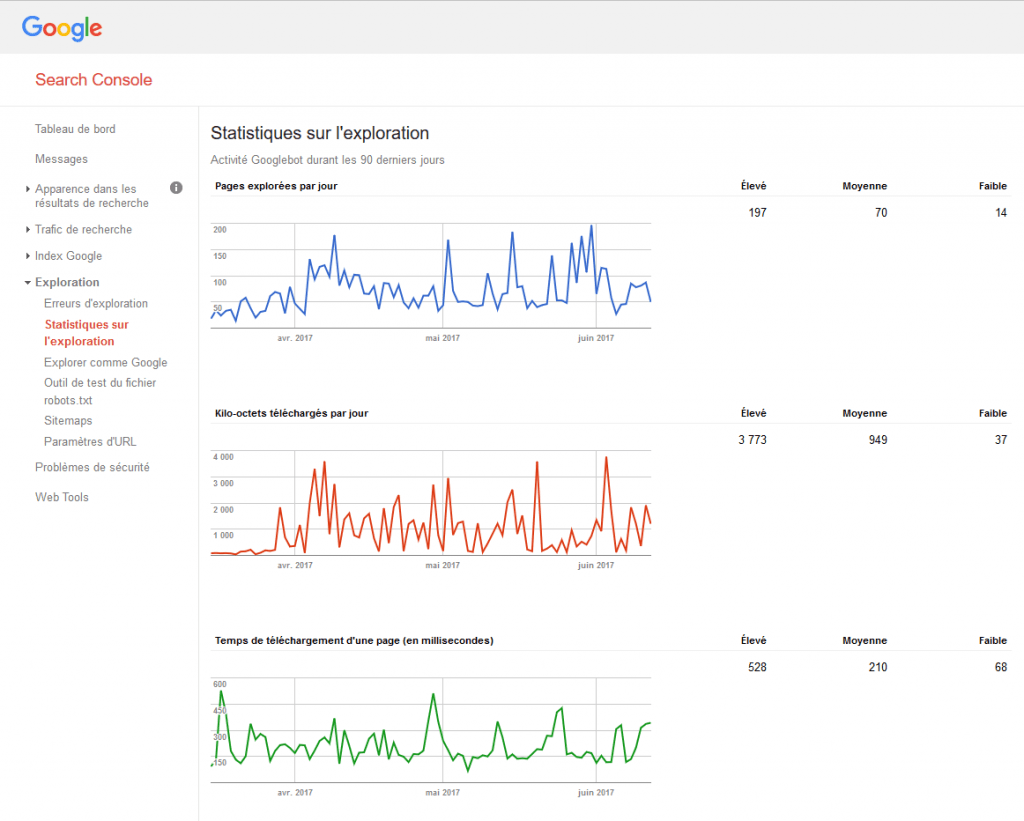
Vous pouvez utiliser la console Google Search Crawl-stat.
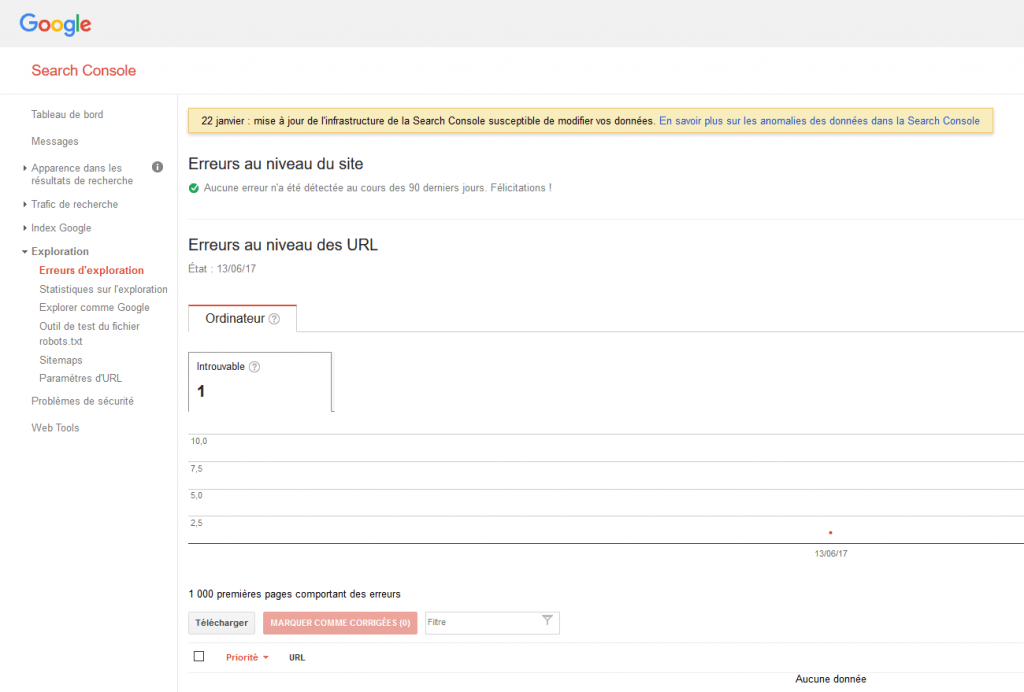
La fenêtre d’erreur Crawl-error est importante : elle va vous indiquer les erreurs que le robot a rencontrées lors du crawl.
Plusieurs types d’erreurs sont possibles, mais ce qui est sûr c’est qu’une page trop lente à charger sera mise en erreur (timeout du bot). Je rappelle que Google ne veut pas passer trop de temps à crawler votre site, il a mieux à faire. Vous trouverez ici plus d’explications sur les erreurs.
Voici par ailleurs, la liste des robots qui sont pris en compte dans le budget de crawl de Google Search console.
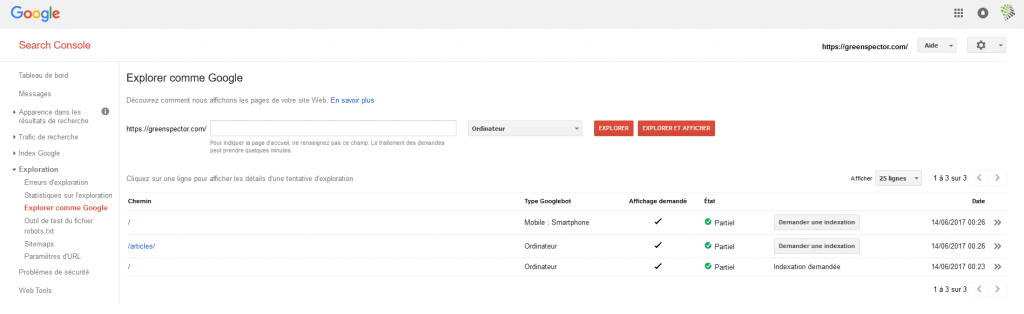
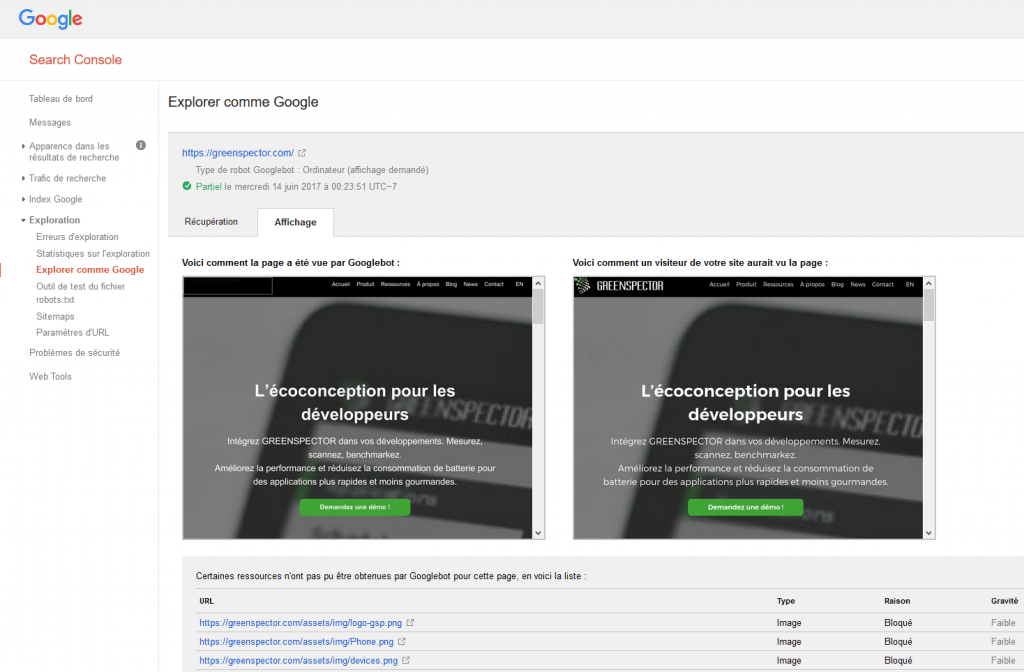
Enfin, vous pouvez simuler la façon dont Google va « voir » votre page. Toujours dans la console Google Search, utilisez l’option Crawl comme Google.
Voila, vous savez maintenant comment Google crawle et voit votre site ! Bon résultat ou mauvais, le référencement n’est jamais acquis et il faut batailler chaque jour. Nous allons donc voir comment améliorer cela.
Améliorez la performance
Temps de réponse du serveur
Comme vous l’avez compris, GoogleBot se comporte comme un utilisateur : si la page met trop de temps à charger, il abandonne et va sur un autre site. Donc une bonne performance va permettre d’améliorer le nombre de pages crawlées par Google. Un chargement rapide laissera au bot le temps de crawler plus de pages. Indexé plus en profondeur, votre site sera mieux référencé.
Reduce excessive page loading for dynamic page requests. A site that delivers the same content for multiple URLs is considered to deliver content dynamically (e.g. www.example.com/shoes.php?color=red&size=7 serves the same content as www.example.com/shoes.php?size=7&color=red). Dynamic pages can take too long to respond, resulting in timeout issues. Or, the server might return an overloaded status to ask Googlebot to crawl the site more slowly. In general, we recommend keeping parameters short and using them sparingly. If you’re confident about how parameters work for your site, you can tell Google how we should handle these parameters.
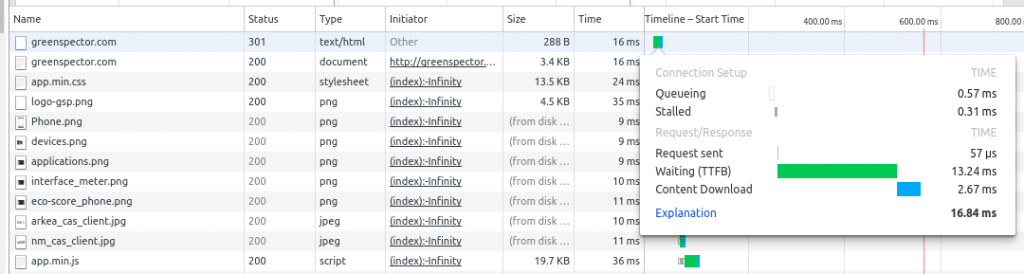
C’est la première limite à respecter : ne pas un dépasser un temps trop long sur le serveur. Trop long ? Difficile de mettre un seuil ! Mais vous pouvez au moins mesurer cette performance avec un indicateur tel que le Time To First Byte (TTFB). C’est le temps entre l’émission de la requête côté client et la réception du premier octet en réponse à cette requête. Le TTFB prend donc en compte le temps de transfert sur le réseau et le temps de traitement côté serveur. Le TTFB est mesuré par tous les outils habituels de gestion de la performance. Le plus simple est d’utiliser les outils de développement intégrés aux navigateurs :
Un seuil normal sera entre 200 et 400 ms. Regardez le temps que vous obtenez, et essayez de le réduire. Comment faire ? Plusieurs paramètres sont à prendre en considération :
La configuration du serveur : si vous êtes sur un hébergement mutualisé, difficile d’agir ; amis si vous connaissez le responsable infra demandez-lui !
Le traitement des requêtes. Par exemple si vous être sous un CMS comme WordPress ou Drupal, le temps de génération des pages PHP et d’accès à la base de données ont un impact important. Vous pouvez utiliser les systèmes de cache comme W3cache ou alors un reverse proxy comme Varnish par exemple.
Un code inefficient côté serveur. Analysez votre code et appliquez les bonnes pratiques d’écoconception.
De cette manière, vous allez faciliter l’accès à vos pages pour vos utilisateurs et surtout éviter les erreurs de crawl de Google.
Performance d’affichage
Difficile de dire à quel point les bots de Google prennent en compte la vitesse d’affichage de votre page mais c’est un paramètre important. Si la page prend 10 secondes à charger, les bots auront du mal à la lire en entier. Comment mesurer cela ? Tout comme pour le TTFB, les outils de développeurs sont utiles. Je vous conseille aussi Web Page Test.
L’idée est de rendre la page visible et utilisable le plus rapidement possible à l’utilisateur. Le plus rapidement possible ? Le modèle RAIL donne des temps idéaux :
En particulier, le R (pour Response) indique un temps inférieur à 1 seconde.
Pour améliorer cela, le domaine de la performance web fourmille de bonnes pratiques. Quelques exemples :
Utiliser le cache client pour les éléments statiques comme les CSS. Cela permet lors d’une deuxième visite d’indiquer au navigateur (et aussi aux bots) que l’élément n’a pas changé et qu’il n’est donc pas nécessaire de le recharger.
Concaténer les JS et les CSS ce qui permettra de réduire le nombre de requêtes. Attention, cette bonne pratique n’est plus valide si vous passez en HTTP2.
Limiter globalement le nombre de requêtes. On voit de nombreux sites avec plus de 100 requêtes. C’est coûteux en termes de chargement pour le navigateur.
Nous aurons l’occasion de revenir dans un prochain article sur la performance web. Au final, si vous rendez votre page performante, ce sera bénéfique pour votre référencement mais aussi pour vos visiteurs !
Aller plus loin avec l’écoconception
La limite de la performance pure
Se focaliser uniquement sur la performance serait une erreur. En effet, les bots ne sont pas des utilisateurs comme les autres. Ce sont des machines, pas des humains. La performance web se focalise sur le ressenti utilisateur (affichage le plus rapide). Or les bots voient plus loin que les humains, ils doivent en effet lire tous les éléments (CSS, JS…). Par exemple, si vous vous focalisez sur la performance d’affichage, vous allez potentiellement appliquer la règle qui conseille de déférer certains codes javascript en fin de chargement. De cette manière la page apparaît rapidement et les traitements continuent ensuite. Or comme les bots ont pour objectif de crawler tous les éléments de la page, le fait que les scripts soient déférés ne changera rien pour eux.
Il est donc nécessaire d’optimiser tous les éléments, y compris ceux qui chargeront une fois la page affichée. On fera particulièrement attention à l’usage du javascript. Google Bot peut le parser mais avec des efforts. On utilisera donc chaque technologie avec parcimonie. Par exemple AJAX a pour but de créer des interactions dynamiques avec la page : oui pour les formulaires ou chargements de widgets… mais non si c’est uniquement pour un chargement de contenu sur un OnClick.
Faciliter le travail du GoogleBot revient à travailler sur tous les éléments du site. Moins il y a d’éléments, plus c’est facile à faire. Donc : Keep It Simple !…
L’écoconception à la rescousse du crawl
L’écoconception des logiciels a pour objectif principal de réduire l’impact environnemental des logiciels. Techniquement, cela se traduit par la notion d’efficience : il faut répondre au besoin de l’utilisateur, en respectant les contraintes de performance, mais avec une consommation de ressources et d’énergie qui soit la plus faible possible. La consommation d’énergie causée par les logiciels (dont votre site web) est donc la pierre angulaire de la démarche.
Comme vous l’avez compris depuis le début de l’article, les bots ont un budget issu d’une capacité limitée en temps mais aussi une facture d’énergie à limiter pour les datacenters de Google. Tiens ? Nous retrouvons ici le but de l’écoconception des logiciels : limiter cette consommation d’énergie. Et pour cela, une approche basée sur la performance ne convient pas : en cherchant à améliorer la performance sans maintenir sous contrôle la consommation de ressources induites, vous risquez fort d’obtenir un effet inverse à celui que vous recherchez.
Alors, quelles sont les bonnes pratiques ? Vous pouvez parcourir ce blog et vous en découvrirez 🙂 Mais Je dirais que peu importent les bonnes pratiques, c’est le résultat sur la consommation de ressources qui compte. Est-ce que les Progressive Web App (PWA) sont bonnes pour le crawling ? Est-ce que le lazy loading est bon ? Peu importe, si au final votre site consomme peu de ressource et qu’il est facile à « afficher » par le bot, c’est bon.
La mesure d’énergie pour contrôler la crawlabilité
Une seule métrique englobe toutes les consommations de ressources : l’énergie. En effet la charge CPU, les requêtes réseaux, les traitements graphiques… tout cela va déboucher sur une consommation d’énergie par la machine. En mesurant et contrôlant le consommation d’énergie, vous aller pouvoir contrôler le coût global de votre site.
Voici par exemple une mesure de consommation d’énergie du site Nantes transition énergétique. On voit 3 étapes : le chargement du site, l’idle au premier plan, et l’idle navigateur en tâche de fond. De nombreuses bonnes pratiques d’écoconception ont été appliquées. Malgré cela, un slider tourne et la consommation en idle reste importante, avec une conso totale de 80 mWh.
On le voit ici, la consommation d’énergie est le juge de paix de la consommation de ressources. Réduire la consommation d’énergie va vous permettre de réduire l’effort du GoogleBot. Le budget énergétique idéal pour le chargement d’une page est de 15 mWh : c’est celui qui permet de décrocher le niveau « Or » du Green Code Label. Pour rappel ici, malgré le respect de bonnes pratiques, la consommation était de 80 mWh. Après analyse et discussions entre les développeurs et le maître d’ouvrage, le slide a été remplacé par un affichage aléatoire et statique d’images : la consommation est retombée sous les 15mWh !
Améliorer la consommation et l’efficience de votre page, c’est bien, mais cela risque de ne pas suffire. L’étape suivante est d’optimiser aussi le parcours de l’utilisateur. Le bot est un utilisateur ayant un budget ressources limité et devant parcourir le maximum d’URL de votre site avec ce budget. Si votre site est complexe à parcourir (trop d’URL, une profondeur trop importante…) le moteur ne parcourra pas tout le site, ou alors en plusieurs fois.
Il est donc nécessaire de rendre le parcours utilisateur plus simple. Cela revient encore à appliquer des principes d’écoconception. Quelles sont les fonctionnalités dont l’utilisateur a vraiment besoin ? Si vous intégrez des fonctionnalités inutiles, l’utilisateur et le bot vont gaspiller des ressources au détriment des éléments vraiment importants. Outils d’analytics trop nombreux, animations dans tous les sens… demandez-vous si vous avez vraiment besoin de ces fonctionnalités car le bot devra les analyser. Et cela se fera surement au dépit de votre contenu qui – lui – est important.
Pour l’utilisateur, c’est pareil : si obtenir une information ou un service demande un nombre de clics trop important, vous risquez de le décourager. Une architecture de parcours efficiente va permettre d’aider le bot et aussi l’utilisateur. Aidez-vous du sitemap pour analyser la profondeur du site.
Enfin, l’exercice d’écoconception des pages ne sera pas efficace si vous avez un site complexe. Il est possible par exemple qu’avec des urls dynamiques un nombre important d’url soit détecté par Google. Vous aurez alors des urls en double, du contenu inutile… Un nettoyage de l’architecture du site sera peut-être nécessaire ?
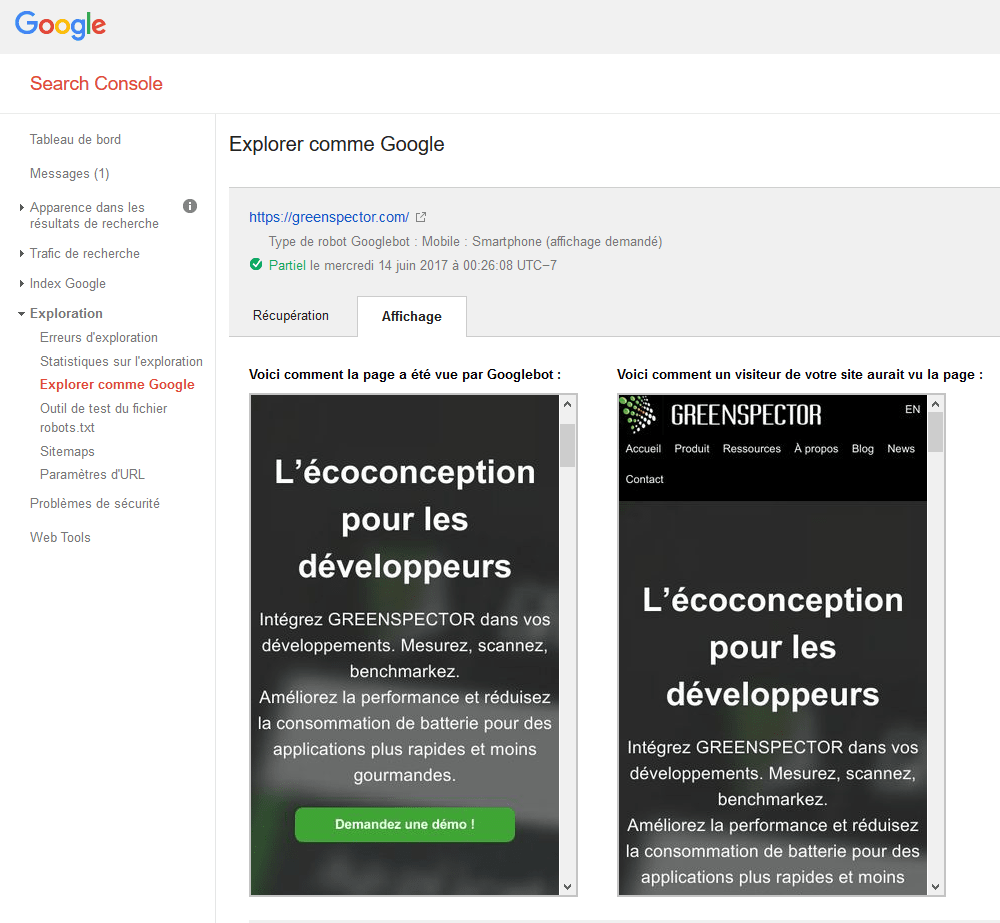
Vous pouvez anticiper la manière dont Google crawle votre site, toujours via la console Search Crawl, avec l’option Fetch as Mobile.
Google propose aussi un site de test pour savoir si votre site est prêt pour le mobile.
La prise en compte de ces contraintes #MobileFirst n’est pas forcément simple pour votre site. Il est probable que cela vous prennent du temps et quelques efforts. Mais c’est le prix à payer si vous voulez avoir un bon référencement dans les prochains mois. En outre, vos visiteurs seront reconnaissants : ils apprécieront que votre site ne décharge plus autant la batterie de leur smartphone.
Pour aller encore plus loin
Reprenons la citation de Google :
Googlebot is designed to be a good citizen of the web.
En tant que développeur ou propriétaire de site, votre ambition doit être de devenir au moins un « aussi bon citoyen du web » que le bot de Google. Pour cela, projetez-vous dans un usage de votre site sur plateforme mobile, mais aussi dans des conditions de connexion bas débit ou d’appareils un peu plus anciens. En réduisant les consommations de ressources de votre site, non seulement vous ferez plaisir au GoogleBot (qui vous récompensera par un meilleur référencement) mais aussi vous donnerez à toute une partie de la population mondiale (y compris dans les pays « riches ») la possibilité d’accéder à votre site. Ne croyez pas que cette approche soit uniquement philantropique. Rappelons que Facebook et Twitter l’appliquent déjà avec les versions « Light » de leurs applis exemple : Facebook Lite.
Un site étant non seulement compatible sur mobile mais prenant en compte toutes les plateformes mobiles et toutes les vitesses de connexion devrait donc normalement être valorisé dans un futur proche par Google. D’autant plus que, plus le site sera léger, moins Google consommera de ressource.
Et comme pour l’utilisateur, la consommation et surtout l’impact sur l’environnement devient de plus en plus important:
Pression des ONG pour réduire ses impacts, par exemple le rapport Greenpeace
Il est certain qu’un site efficient et répondant uniquement au besoin de l’utilisateur sera mieux valorisé dans le classement SEO de Google (et des autres).
Conclusion
Le référencement de votre site web par Google s’appuie en partie sur la notion de crawling : le robot parcourt les pages de votre site. Pour cette opération, il se fixe un budget de temps et de ressources. Si vos pages sont trop lourdes, trop lentes, le crawling ne sera réalisé que partiellement. Votre site sera mal référencé.
Pour éviter cela, commencez par prendre l’habitude d’évaluer la « crawlabilité » de votre site. Puis mettez en place une démarche de progrès. En première approche, regardez ce que vous pouvez obtenir à l’aide des outils de performance classiques.
Puis réfléchissez en termes de MobileFirst : appliquez les principes de l’écoconception à votre site. Simplifiez le parcours utilisateur, enlevez ou réduisez les fonctions inutiles. Mesurez votre consommation d’énergie et mettez-là sous contrôle. Au prix de ces quelques efforts, vous obtiendrez un site mieux référencé, plus performant, apprécié des utilisateurs.
De nombreux sites web ayant cédé à l’obésité (trop de requêtes, des scripts superflus…), il est urgent d’anticiper l’évolution des algorithmes de référencement de Google, qui suivent désormais les mêmes objectifs que les utilisateurs, en demandant plus de performance ET moins de consommation d’énergie : en un mot, de l’efficience.
Expert Sobriété Numérique Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», … Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …) Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels
GREENSPECTOR permet de détecter des comportements des logiciels ayant un impact sur la consommation de ressources (énergie, mémoire….). Nous utilisons pour cela un ensemble de techniques permettant d’être le plus précis dans les constats pour permettre d’obtenir des gains importants et cela avec peu d’effort. L’analyse de code et la détection de patterns consommateurs fait partie de ces techniques.
Généralement, l’analyse de code se focalise à une détection syntaxique (c’est ce que l’on peut voir dans une IDE quand on tape du code et que l’IDE nous propose une autre écriture). Nous avons initialement utilisé ces techniques classiques d’analyse de code mais les résultats ne nous semblaient pas satisfaisants. En effet, nous obtenions trop de violations (le développeur pouvait être noyé dans trop de violations), et parfois des faux positifs. Au-delà de cela, de simples règles syntaxiques ne permettaient pas de détecter des règles poussées (ayant un impact sur la consommation de ressources) comme la détection des Wake lock sur Android. C’est la raison pour laquelle nous avons choisi de partir sur une autre technique d’analyse. Voici notre retour d’expérience.
Dès leur apparition dans les années 50, l’analyse du code source écrit dans un langage fut rapidement perçue comme un enjeu d’importance. En effet, LISP, un des tous premiers langages (1956) est par nature autoréférentiel et permet à un programme de s’analyser lui-même. Dès lors que l’ordinateur personnel s’imposa, il ne fallut qu’une dizaine d’années pour voir apparaitre des IDEs, comme Turbo Pascal de Borland, qui proposa de plus en plus de services d’assistance au programmeur. Pendant ce temps Emacs montrait la voie : analyse de code (grâce au LISP), code en couleur, etc… L’analyse du code source lors de son écriture est maintenant partie intégrante de l’environnement de développement mis en place lors de l’initiation d’un projet : Jenkins, Eclipse propose des services sans cesse plus performants. GREENSPECTOR est l’un de ces assistants qui assiste le développeur à écrire une application plus efficiente en consommation énergétique.
Plonger dans les entrailles du code
GREENSPECTOR propose entre autre d’analyser le code source afin de trouver des formes, des façons d’écrire qui pourraient être améliorées en termes de performances d’exécution, de consommation mémoire ou de consommation réseau, trois facteurs ayant une forte incidence sur la consommation d’un smartphone, permettant à votre client de pouvoir profiter de celui-ci toute la journée.
Hello world de la détection de pattern
Prenons un exemple stupide mais simple. Chacun reconnaitra qu’il est plus malin d’écrire :
var arraySize = myarray.length;
for (var i = 0 ; i < arraySize ; i++) {
aggr += myarray[i];
}
que
for (var i = 0 ; i < myarray.length ; i++) {
aggr += myarray[i];
}
Dans le second exemple, on aura un appel à la méthode length à chaque test de la boucle. Dans un tableau de taille conséquente, cet appel de méthode peut vite devenir coûteux.
AST
Bien évidemment, on ne peut pas analyser le texte brut du code, mais une représentation de données adaptée à la manipulation par programmation. On appelle cette représentation un AST, pour Abstract Syntax Tree. Comme son nom l’indique, un AST est un arbre… On verra plus tard pourquoi c’est important.
L’AST de notre premier bout de code pourrait ressembler à quelque chose dans le genre :
Obtenir cet AST n’est pas évident. En Java, on dispose de JDT, PDT pour respectivement Java et PHP. Ces librairies sont éprouvées, et même si leur fonctionnement est un peu difficile à appréhender et leur logique laisse parfois à désirer, elles restent assez efficaces.
Chez GREENSPECTOR, nous avons choisi d’utiliser Scala pour réaliser notre outil d’analyse de code. Scala, la puissance du fonctionnel, les avantages de la JVM. Afin de réaliser des analyses sur l’AST, nous avons écrit notre propre grammaire en Scala, qui est un mapping des grammaires JDT ou PDT. Cette grammaire, utilisant les cases class de Scala, nous permet de bénéficier du pattern matching que ce langage a piqué à OCaml, lors de sa conception.
Ainsi, une affectation de variable est ainsi définie en Scala :
case class AssignmentJava ( id:Long, vRightHandSide : JavaExpression, vLeftHandSide : JavaExpression, vOperator : JavaAssignmentOp, lne : (Int,Int)) extends JavaExpression
Tandis qu’un pattern-matching (sorte de switch-case au stéroïdes) sur cette structure ressemble à
case AssignmentJava( uid, vRightHandSide, vLeftHandSide, vOperator, lne) => ...
A droite, on peut faire ce qu’on veut des variables uid, vRightHandSide, vLeftHandSide, vOperator, …
Cette façon de faire est très puissante pour analyser un arbre.
Détecter les boulettes
Maintenant que nous avons notre arbre, il va falloir détecter des problèmes qu’on voudrait remonter à l’utilisateur. Problème, on ne sait toujours quel problème on va lui remonter. Donc écrire cette détection dans le programme en Scala, avec le pattern-matching n’est pas très flexible, car il faut sans-cesse changer le programme. De plus, ce n’est pas forcément simple à écrire.
En bon fainéant, nous voici à la recherche d’une méthode moins fastidieuse. En fait, je vous ai menti : pour être fainéant, Scala et son pattern-matching n’est pas adapté. Or, qui dit simplicité, dit requête. Eh bien voilà, il nous faut un langage de requête ! Comme SQL ou les regexp. Un truc où on décrit juste ce qu’on cherche, et paf, le système nous le ramène !
BDD Graphe
Heureusement, le monde sans cesse plus foisonnant de l’Open Source arrive à la rescousse : Neo4j est un serveur de base de données orienté graphe. Même s’il est plus conçu pour analyser qui sont vos amis sur Facebook ou avec qui vous discutez sur Twittter, on peut l’utiliser pour une raison simple : un arbre est un cas particulier d’un graphe ! Mais surtout, Neo4j est doté d’un langage parfait pour un fainéant : Cypher. Cypher est le langage de requête de Neo4j, il est totalement conçu pour trouver n’importe quoi dans un graphe.
D’où l’idée de mettre notre AST dans Neo4j et d’utiliser Cypher pour trouver ce que l’on cherche.
Trouver du code mal écrit
C’est souvent moins de 20% du code qui mobilise 80% du CPU la plupart du temps !
Un AST n’est juste qu’une représentation arborescente d’un texte, la densité d’informations sémantiques restant limitée. Afin de pouvoir analyser plus précisément le code et détecter des motifs intéressants et/ou difficiles à voir, on a besoin d’accroitre la densité sémantique du code. Pour se faire, on va transformer notre arbre en graphe, en créant des liens entre éléments de notre AST. Par exemple, nous allons pouvoir créer des liens entre des nœuds de type ‘Déclaration de fonction’, de sorte que l’on sache quelle fonction appelle quelle fonction. Bien évidemment, chacun de ces appels sera aussi relié à l’endroit où cette fonction est appelée.
On appelle cela le ‘Graphe d’Appel‘ notons que cette construction est plus aisée à faire dans certains langages que d’autres. Ainsi Java, de par sa structure et ses déclarations de type obligatoires nous permet de retrouver plus facilement le graphe d’appel que des langages comme, disons, au hasard, Javascript ou PHP 😉
La difficulté consiste à ne pas se tromper d’appel : combien de méthodes différentes vont s’appeler ‘read’ par exemple ? Potentiellement beaucoup. Il faut donc s’assurer que l’on relie bien les 2 bonnes fonctions, et pour se faire déterminer quel est le type de l’appelant, dans les langages orientés objet.
Connaitre le graphe d’appel, combiné à d’autres analyses, permet de savoir quel partie de code s’exécute le plus souvent, car on en a l’intuition, mais on ne le sait pas toujours, c’est souvent moins de 20% du code qui mobilise 80% du CPU la plupart du temps. En connaissant les parties du code les plus souvent exécutées, on pourra attirer l’attention du développeur sur des optimisations particulières à faire sur des portions critiques du code.
De même pour économiser de la mémoire, il faut utiliser plus intelligemment les variables que l’on déclare. En retrouvant leurs déclarations et les liens avec leur utilisation, on devient capable d’indiquer comment optimiser l’utilisation de la mémoire.
Illustrons ce que nous avons abordé avec un exemple simple, le helloworld de la détection de pattern. On observe souvent, en java, des boucles itérant simplement un tableau, en vérifiant que l’index est strictement inférieur à l’index du tableau. Cet exemple est améliorable, car l’appel à la méthode .size() est couteux et pourrait être mis « en cache » dans une variable.
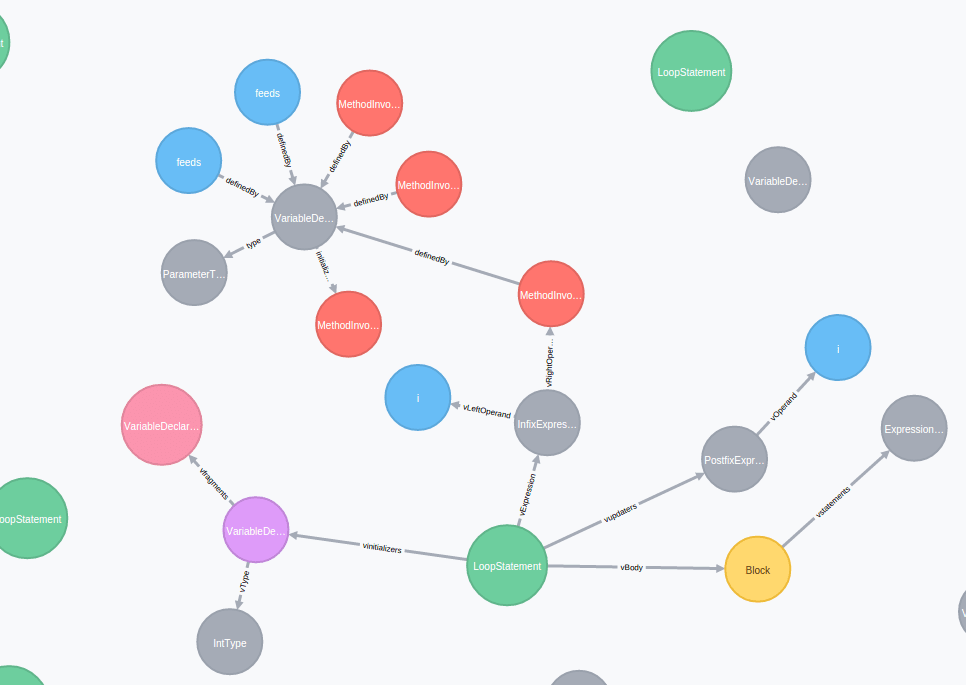
Le langage cypher dont nous avons parlé tout à l’heure nous permet de détecter à coup sûr ce genre de « forme » de code :
match (n:LoopStatement) where n.loopType = "ForStatementJava" with n match (n)-[:vExpression]->(i:InfixExpression)-[vRightOperand]->(m:MethodInvocation) where m.methodName = "size" return n;
En gros, on lui demande de trouver un for classique en Java, ayant dans l’updater du for, un appel de méthode size()
Conclusion
La représentation sous forme de graphe modifiable offre une grande flexibilité pour l’analyse du code. Elle permet d’analyser le code avec la profondeur d’analyse choisie et d’améliorer sans cesse la qualité d’analyse du code.
Au sein de GREENSPECTOR, de par sa simplicité, sa puissance et son intuitivité, le langage de requête Cypher a vite été adopté et la montée en compétence fut rapide.
Nos règles sont maintenant beaucoup plus cohérentes et avec moins de faux positifs. A vous de le découvrir en lançant une analyse de code avec GREENSPECTOR !
De notre côté, il nous reste encore à explorer toutes les possibilités de cette architecture qui nous permettra à terme de réaliser des analyses de haut niveau.
Expert Sobriété Numérique Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», … Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …) Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels
Webp est le nouveau format d’image proposé par Google, qui promet une réduction de 30% à 80% de la taille de transfert. De plus, le format serait plus adapté aux processeurs actuels. Mais qu’en est-il de la consommation d’énergie sur l’appareil de l’utilisateur ?
Le format Webp
Webp est un format matriciel comme le PNG ou le JPEG. Il supporte des compressions sans perte (lossless) comme le PNG mais aussi avec perte (lossy) comme le JPEG. Ce format est actuellement pris en compte par Chrome, Chrome pour Android, et Opera. Cependant la controverse vient de la fondation Mozilla qui considère que le format n’offre pas autant d’avantages qu’annoncé.
Au passage, Mozilla travaille de son côté sur une optimisation du JPEG : MozJPEG. Voici un lien pour comprendre comment gérer ces problèmes d’implémentation : Google WebP Mais qu’en est-il effectivement de l’efficience de ce nouveau format ? La mesure de l’énergie consommée pour afficher ces images va permettre de répondre à cette question !
METHODOLOGIE DE MESURE
Pour cela j’utilise mon outil favori (ce n’est pas une surprise), à savoir le service Power Test Cloud de GREENSPECTOR.
La méthodologie est la suivante :
La mesure est faite sur un smartphone réel, un Nexus 6, hébergé et géré par GREENSPECTOR ;
On lance Chrome et on accède aux exemples d’images donnés par Google ;
On itère 2 fois, parce que 2 mesures valent mieux qu’une.
Avant d’aller plus loin, nous pouvons émettre nous-mêmes quelques critiques sur notre protocole :
On utilise les images de Google : sont-elles vraiment représentatives ? On supposera que oui.
On évalue le coût unitaire d’affichage des images et non pas leur intégration dans une page web plus globale. En même temps, on est là pour ça.
Comparaison des formats : Webp (lossless et lossy) versus PNG
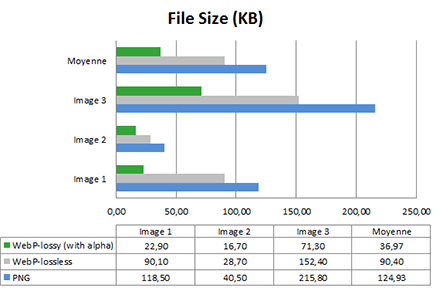
Pour cet test, nous avons pris les 3 premières images de la galerie Google. Vérifions d’abord la taille des images :
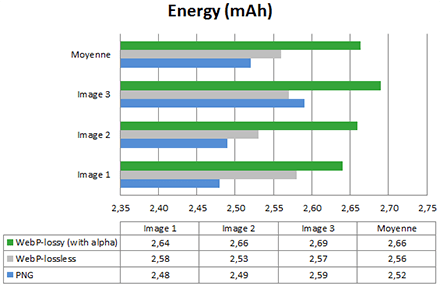
Le résultat est très net : les images Wbep sont en moyenne 27% plus légères que le PNG, et même 70% pour le lossy. Les promesses sont pour l’instant au rendez-vous. Mais regardons l’énergie consommée sur le smartphone pour lorsqu’il affiche ces images dans le navigateur :
Aïe. En moyenne, il y a WebP engendre 1,5% de consommation d’énergie supplémentaire. Il y a un gain uniquement pour l’image 3 – et encore, en comparons le Webp lossy au PNG. Pour l’image 1 on a une perte de 3,8%. Enfin on constate que le Webp lossy avec transparence est encore plus consommateur que le Webp lossless. C’est surprenant !
Au final, le PNG est plus intéressant pour la consommation d’énergie. Si vous vous focalisez uniquement sur les gains réseaux, alors WebP est plus intéressant. Le constat est encore plus fort pour le Webp lossy avec transparence. Cela peut s’expliquer par un algorithme de rendu moins efficient que le PNG, qui annule tous les gains d’énergie apportés par la réduction de l’impact réseau.
Comparaison des formats « lossy » : Webp versus JPEG
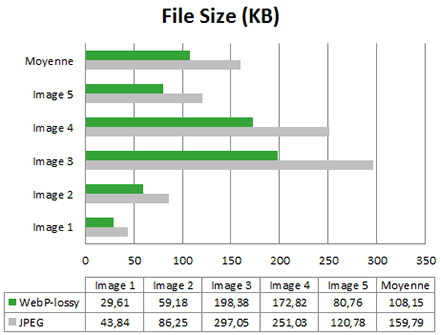
Pour ce test, nous avons testé les 5 images de la galerie de Google Vérifions d’abord la taille des images.
Là aussi la promesse est tenue : le gain de taille apporté par Webp est en moyenne nos 30%. Vérifions maintenant la consommation d’énergie.
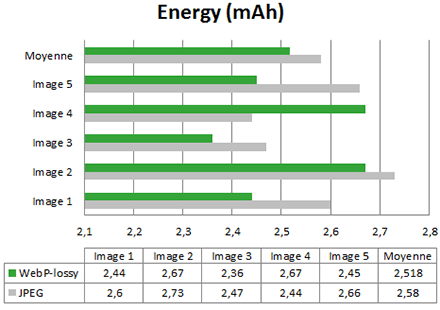
Dans 4 cas sur 5, les gains apportés par Webp par rapport à JPEG sont intéressants (entre 2% et 8%). A cause du cas particulier de l’image 4, la moyenne des gains s’établit à 2,4%.
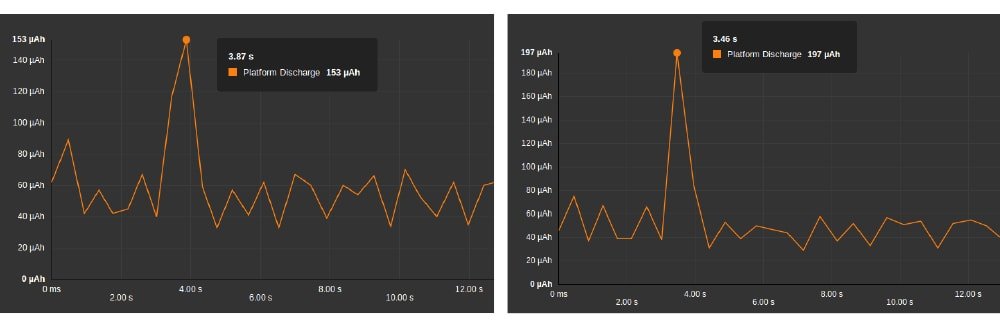
Si on regarde plus précisément les courbes de consommation d’énergie, on constate effectivement que le pic de consommation est plus bas pour Webp :
On remarque globalement que Webp sollicite moins la batterie que JPEG.
CONCLUSION
Il est clair que le format Webp permet d’obtenir une taille d’image plus faible que les autres formats. C’est bénéfique pour le réseau internet en général, les opérateurs telecom en particulier, et les utilisateurs finaux tout spécialement.
Nous avons aussi identifié des gains d’énergie allant jusqu’à 8% pour les images lossy par rapport à du JPEG. Cependant dans certains cas minoritaires pour le lossy et dans tous les cas pour le lossless, nous avons identifié des consommations d’énergie plus importantes pour Webp que pour les formats traditionnels. Si vous voulez des images lossless (par exemple pour des logos, des images avec du texte…), alors le PNG reste meilleur en termes d’énergie.
Explication : comme les images sont plus légères, il semble que la cellule radio soit moins sollicitée et donc qu’il y ait moins d’énergie consommée. Cependant quand on regarde l’occupation CPU, Chrome passe du temps dans le traitement pour la décompression du Webp. Sur un smartphone, les gains sur le réseau sont donc limités, voire annihilés, par le coût du traitement CPU supplémentaire.
Conclusion de la conclusion : Les gains de taille apportés par le Webp sont réels pour le réseau. Associés à une réduction – certes faible – de la consommation d’énergie, ils font de WebP un format intéressant pour l’efficience en tant qu’alternative au JPEG. En revanche, pour l’alternative au PNG, il faudra attendre.
Enfin notons que dans ce domains les travaux sont nombreux. Ainsi pour l’alternative au JPEG, une convergence vers d’autres améliorations technologiques comme le HTTP2, pourrait permettre des gains plus importants encore.
Expert Sobriété Numérique Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», … Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …) Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels
La maîtrise de la consommation énergétique est un domaine de plus en plus important dans le développement d’applications mobiles. Les dernières versions d’Android intègrent par exemple un mode doze dans lequel le smartphone interrompt les traitements et ne les réveille que périodiquement, mais cela n’est pas suffisant et les développeurs d’applications ont également un rôle à jouer. À l’échelle d’une application, il est possible d’améliorer la consommation énergétique en commençant par bien choisir ses structures de données.
Expert Sobriété Numérique Auteur des livres «Green Patterns», «Green IT – Gérer la consommation d’énergie de vos systèmes informatiques», … Conférencier (VOXXED Luxembourg, EGG Berlin, ICT4S Stockholm, …) Fondateur du Green Code Lab, association nationale de l’écoconception des logiciels
Greenspector may use cookies to improve your experience. We are careful to only collect essential information to better understand your use of our website.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.